GenerateDeltaTable configuration¶
In order to track row-level changes between versions of a Delta table in an optimized way, Change Data Feed on Azure Databricks option has been included in Sidra through the GenerateDeltaTable column in the Entity table.
In the next table, the actions of Change Data Feed are depicted:
| Changes | Databricks - Change Data Feed |
|---|---|
| Fields | TABLE_COLUMNS + _change_type + _commit_version + commit_timestamp |
| Insertions | Adds a new row with the values of the source table and with _change_type = insert |
| Updates | Adds two rows, one with the previous data and change_type= update_preimage; and another one with the updated data with _change_type = update_postimage. Both are with the same _commit version and _commit_timestamp |
| Deletions | Adds a new row with the data and with _change_type= delete |
Configuration¶
Considerations¶
The metadata created after a first ingestion is needed to be able to modify the Entity property GenerateDeltaTable. When the metadata pipeline is executed, and the metadata created, the metadata pipeline must be executed again to update the configuration for the tables. For executing the pipeline, two ways are ava:
- Directly executing the metadata pipeline.
- Executing the Orchestrator if the schema evolution is activated by the Sidra Web -note that in this last case the question Do you want the metadata to be refreshed automatically with each data extraction? should be marked as
true.
Configuration steps¶
For the configuration, follow the next steps:
- Set the Entity property
GenerateDeltaTabletotrue. - Update the
LastUpdateddate of the Entity to be greater than theLastDeployeddate. - Execute the orchestrator for the DIP or the
FileIngestionDatabricksADF pipeline for the Provider. - After the execution, the Databricks table history should have changed. Execute in Databricks this to visualize it:

By updating the data in the source (by modifying, creating, or removing rows), the tracking table in Databricks should update. To check it, execute:
%sql SELECT * FROM table_changes('[provider].[table]', '2022-04-21 05:45:46')
# Timestamp is indicated to review the specific changes
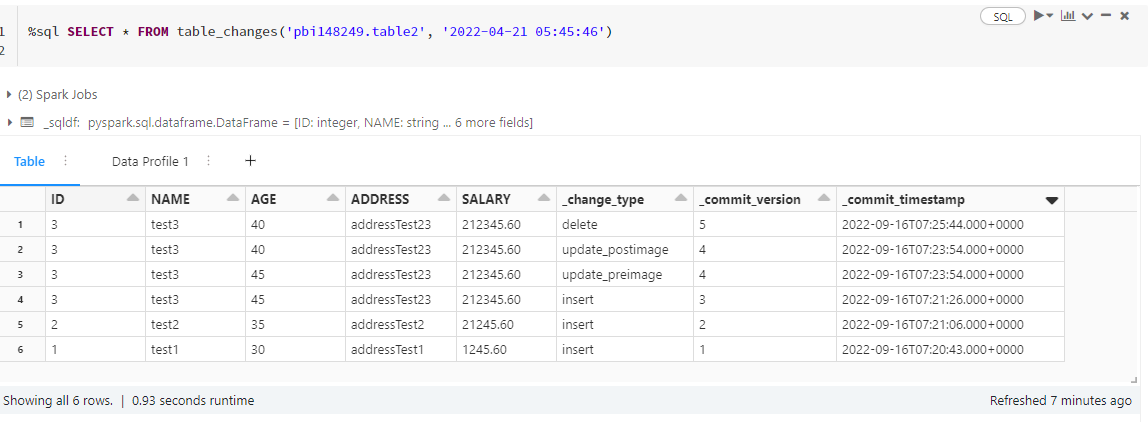
In the example above, the delta table view appears with 3 inserts, one update and one delete.
Databricks creates a folder (_change_data) in the same directory of the table to store the changes done in the table. These changes are stored in parquet format.
Scenarios with other parameters of Entity table¶
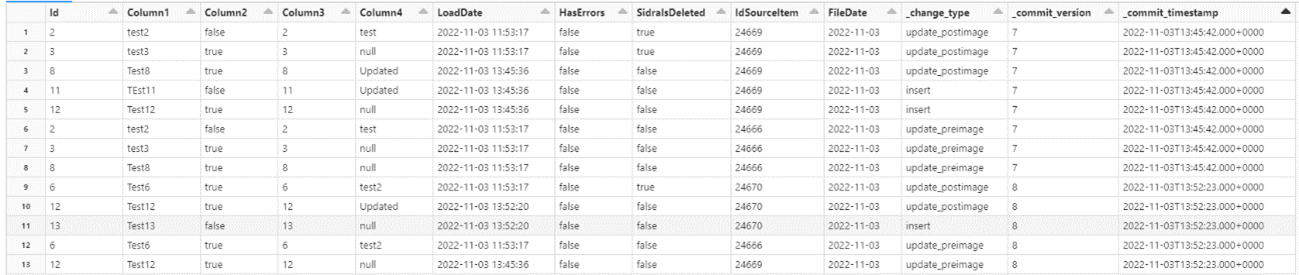
The displayed tables are the ones generated by Databricks after setting the delta.enableChangeDataFeed to true in the Databricks table (as shown above in the first image).
Do not confuse with consolidation mode options on Data Products, configurable through pipelineExecutionProperties column.
ConsolidationMode as Snapshot¶
In this consolidation mode option, since we are appending all the data for the Asset, the Change Data Feed will identify everything as an insert. Deletions will be identified the same way, since we set a deletion with a new row with all values to NULL except for the Id and the SidraIsDeleted values.

ConsolidationMode as Merge¶
For this case:
- Inserts are identified with the operation in one line.
- Updates are identified with the operation in two lines.
- Deletions in data source are represented as an insert with all values to NULL except for the Asset id and the
SidraIsDeletedastrue.