Quick start¶
Information
Ensure you have a Sidra license before starting the process. For assistance or to obtain a license, please contact us at [email protected].
Follow the next steps to start with Sidra:
-
Deploy Sidra through Supervisor Service. The Supervisor will deploy the services that compound Sidra and enable the management of updates for each service.
Dive deeper in Supervisor and Sidra deployment
To install Supervisor, execute a PowerShell script that creates applications in Azure Microsoft Entra ID with the capability to deploy the infrastructure. Following this, the infrastructure is established using an ARM template. After deployment, we can access the Supervisor web interface to verify credentials, which then triggers the automatic installation of Sidra.
-
Once the installation has finished (see Azure resources deployed), a new screen with all the installed and additional services is displayed. Install the desired services depending on your business needs.
- Access to Sidra Web Manager.
-
Create your first Data Intake Process (DIP). A gallery of data source connectors is available on Sidra Web. Select yours and begin configuring the DIP. The result of this stage is the optimized ingestion of raw data in Azure Data Lake Storage Gen2, which is part of the Data Storage Unit in Sidra terms.
Dive deeper in Data Intake Process
This step creates the necessary metadata from your data (see available data source connectors) and stores it in the Sidra database organized through the metadata system.
During a DIP, an enriched ingestion process occurs behind the scenes, performed by preconfigured Azure Data Factory extraction pipelines and a DSU ingestion Databricks notebook. Some of the actions applied to your data are:
- Register of Assets.
- Metadata structure is retrieved from Sidra's API (from Sidra database).
- Consolidation mode and incremental load options of data are set up.
- Data Catalog, available with AI search in the Sidra Web Manager, is generated.
- Data quality validations (if installed) and anomaly detection are performed.
- PII detection is applied.
-
With the raw data optimally organized in the data lake, Data Products can effectively develop business cases based on this information. Use Data Domain template from Sidra to setup a SQL database including a Databricks step with custom querying of your data.
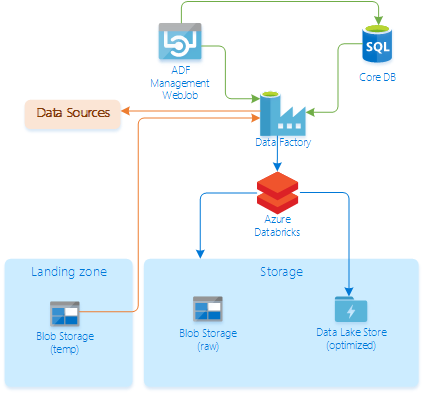
For ingestion of CSV files, a different data intake applies to this process, data intake via landing zone. Instead to perform the Data Intake Process creation through the Sidra Web manager, follow this process performed by Sidra's API and Azure Portal.