Data Syncs¶
In Sidra terms, the Sync Mode is the template used to create a Data Sync (the pipeline template used to create the ADF pipeline). The Data Syncs performs the following actions:
- Export the raw data from the DSU to the Data Product storage (raw storage container).
- Copy the data to the Data Product Databricks as delta tables.
- An orchestrator Databricks notebook (optional) that executes any custom user logic that needs to be performed before data is moved to SQL.
- Create staging tables in the Data Product database based on the queries in
StagingConfigurationwith the needed views or aggregations. - An orchestrator SQL stored procedure executes business logic to create the final production tables in the Data Product database.
- This Data Product integrated with Sidra shares the common security model with Sidra Service and uses Identity Server for authentication.
After the deployment of a Data Product, ADF pipelines are generated:

CopyEntityToStorageCopyEntityToDatabricksRunIndexMaintenance
Similarly, notebooks in Databricks are automatically generated:

CreateTables.pyExtractToStagingTables.pyLoadDataInDatabricks.py
Process¶
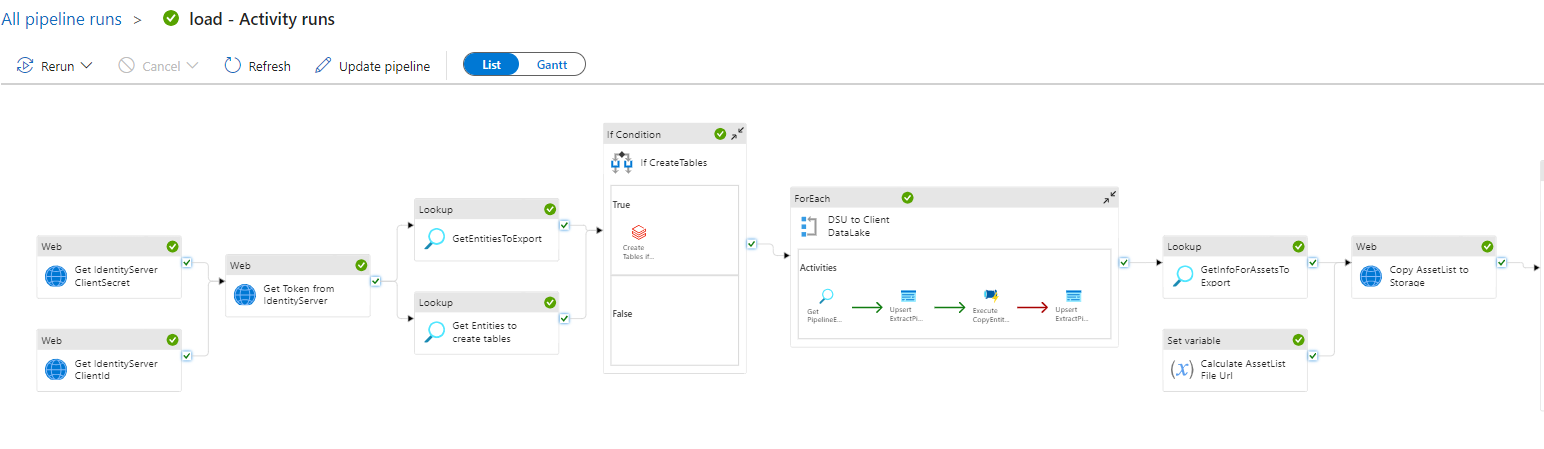
Once a new Data Sync has been configured, the following steps will be completed:
- Step 1: The list of Entities to query and export from the Data Lake (DSU) is retrieved. This list will also be used for creating the tables in the Data Product Databricks.
- Step 2: If there are any Entities requiring to create tables in the Data Product Databricks, a notebook called
CreateTables.pyin the Data Product Databricks is executed. - Step 3: For each Entity to export, through the
CopyEntityToStorageADF pipeline, the data is first copied from the DSU into the Data Product storage (in raw format), through a call to/querySidra Service API endpoint. - Step 4: For each Entity to export, through the
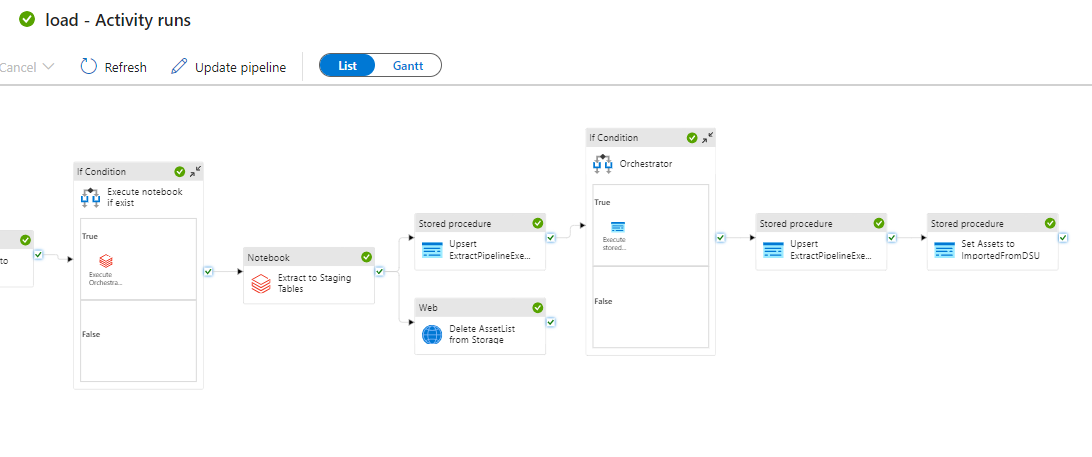
CopyEntityToDatabricksADF pipeline, the data is copied to the Data Product Databricks as delta tables (a notebook calledLoadDataInDatabricks.pyis executed for this data operation). - Step 5: An entry point notebook, or orchestration notebook, whose name is passed as a parameter to the pipeline, is executed. Here the user is able to add any custom querying logic for aggregating and correlating any data that has been made available as Databricks delta tables. The queries to execute in this notebook will be read from the configured data on the
StagingConfigurationData Product table. - Step 6: Another Databricks notebook, called
ExtractToStagingTables.py, is executed to load the data into the SQL staging tables, therefore making it available for further processing. - Step 7: The orchestrator SQL stored procedure is called. This stored procedure executes business logic to read from the staging tables and create the final production data models.
- Step 8: Finally, the Asset status is changed to
ImportedFromDataStorageUnit, or status 3, meaning that the Asset has been imported from the Data Storage Unit into the Data Product database.
When a pipeline is being executed, the Sync job will provide several parameters to the pipeline. Depending on the sync behaviour, the pipelines can be in different status.
Update the Sync behaviour of pipelines
Update the Sync behaviour from the endpoint:
Check here the available endpoints.Custom pipelines for Data Products¶
ADF components (datasets, triggers and pipelines) for custom pipelines in Data Products are managed by Data Product API endpoint:
This endpoint uses information stored in the metadata database to build and programmatically create the ADF components in Data Factory, which means that Data Products need a metadata database to store the information about ADF components.
Multiple pipelines per Entity¶
A new pipeline execution status (Sidra.ExtractPipelineExecution) has been implemented, which tracks the execution status per Asset per Entity and Data Product pipeline. This Sync behaviour checks those Assets that have not been added yet for a specific pipeline, but which are in the Assets table. These Assets will therefore be considered for the next Data Product pipeline load. If the Asset status for these Assets are in state 3 (ImportedFromDataStorageUnit), then this status will be ignored, because now the table will refer to the ExtractPipelineExecution status.
This table is being filled by the corresponding status (extracting, staging, finished, error) in by an activity in the Data Product pipeline. These Data Product pipeline templates use this PipelineSyncBehaviour.
This SyncBehaviour LoadUpToLastValidDate works similarly to type LoadPendingUpToValidDate, but checking the ExtractPipelineExecution to work with multiple pipelines. LoadUpToLastValidDate is the mandatory PipelineSyncBehaviour to configure if it is required to execute multiple Sync Mode. In this behaviour, Sync retries not finished Assets by pipeline (default limit attempts= 3). This can be changed through App Service configuration setting up the Sync.AssetRetries key.
When configuring the Sync behaviour for executing different Sync Mode per Entity, we also need to consider the following:
- The Data Product templates are automatically filling in the value in the table
ExtractPipelineExecution. This is done by an internal stored procedure called[Sidra].[UpsertExtractPipelineExecution]. This step is automatically performed, without any need to add any configuration parameter to the Data Product pipeline. - This insertion to the
ExtractPipelineExecutiontable is performed at the beginning of the corresponding Data Product template.
Mandatory Assets¶
The same data extraction pipeline can be used to extract several Assets from different Entities. As in Sidra Service, EntityPipeline table is used to associate the same Data Product pipeline to several Entities.
For the Sync process to copy the data from the DSU it will be necessary to assign all Entities to their corresponding pipelines.
Sidra also provides support for defining mandatory Assets, which means that the extraction pipeline will be executed only if all the Assets marked as Mandatory are present in Sidra Service, so there is an Asset at least for each of the mandatory Entities. For those Entities for which it is not needed that Assets are loaded in Sidra Service, it is not necessary to mark the Mandatory cell in the Sidra Web.
Step-by-step
Associate Entity-Pipeline
Please, refer to the specific tutorial for associating Entity and pipelines through Sidra Web or enable mandatory Assets.
Available pipeline template¶
The available Sync Mode provided by Sidra is Copy Entities to Databricks and SQL Database, which can be used to accelerate the data movement between the DSU and the Data Domain. The Sync Modes are provided as-is and with the only purpose that are defined for. The platform is open to create your own pipelines with your own activities, as the same that happens in Core but here your pipeline should have the defined parameters explained in previous points to allow that can be raised by Sync job.
SQL Staging Table generation¶
By default, for all the pipeline templates that are dropping the content to an SQL database, the destination staging table is auto-created by the data extraction pipeline, via the execution of a stored procedure provided by Sidra.
As the tables are recreated in every load, they don't include keys or indexes. These changes need be explicitly included inside the orchestrator stored procedure called by the pipeline. This stored procedure also needs to ensure that the tables are optimized for the queries that will be executed.
In addition, another stored procedure is called within both pipelines that inserts the tracked execution values in the ExtractPipelineExecution table.
Summary
Summarizing all the concepts above, the extraction pipelines will be launched by the Sync job once it has checked the following conditions:
- The PipelineSyncBehaviour is not Ignored.
- The pipeline is not associated to a Provider through an Entity that is marked as disabled.
- The pipeline is not being executed.
- There are Assets ready to be exported i.e., the AssetStatus is MovedToDataLake or ImportingFromDataLake.
- If the relationship between the pipeline and the Entity contains the flag IsMandatory= true, and the date of the Asset to be exported are between the StartValidDate and EndValidDate of the Entity.
- There is at least as many Assets ready to be exported as the number of Assets stored in the Entity field FilesPerDrop.
Some considerations more:
- An additional field IsMandatory is included in the association between Pipeline and Entity and must be taken into account when setting up this relation using the tutorial How to associate an Entity with a pipeline.
- Pipelines in Data Products has an additional field -ExecutionParameters-, which must be configured.