Sidra Data Platform (version 2022.R3: Lazy Lady William)¶
released on Nov 23, 2022
The focus of this latest release has been to improve the technical foundations of the plugin system to allow for the full end-to-end lifecycle that will be unlocked on the next release. While that might not sound particularly exciting, it is the key to enable the plugin editing and upgrade functionality that will be released in the next version.
In addition to that, a very significant roadmap item is released today in the form of our new DSU Ingestion process. This process has been re-designed and simplified, so that the pre-generation of the transfer queries for ingesting data into the DSU is no longer needed, and it is now offered as a plugin to reduce the need to upgrade the Sidra version for updates and technical evolution on the DSU Ingestion process.
Also, this release is marked with important improvements in the user experience of Sidra Web, with the vastly improved global search mechanism in the Data Catalog and the new DSU management pages being the most visible of them. There are also many smaller refinements and UX/UI quality of life improvements through all the application that make the usage of Sidra's interface more pleasant and effective than ever.
This release also offers an improved PII detection and classification module for Data Intake Processes, so that Attributes, Entities and Providers can be classified by the presence or absence of PII in the data of the underlying ingested Assets into the platform.
Sidra 2022.R3 Release Overview¶
- New DSU Ingestion module
- Oracle, MySQL and MariaDB connector plugins
- Google Analytics Universal connector plugin
- Connector modularization
- PII detection and classification for Data Intake Processes
- New Data Catalog global search and search by Attributes
- Windows Authentication for SQL server plugin
- New DSU pages in Sidra web
- New scenarios for complex Excel Data Intake
- New Python client library
- Attribute and Entity name sanitization via API
- Detect and prevent Data Product record mismatch to avoid duplicates in Staging
- Force install a specified MaxVersion of Azure CLI
- New template for PipelineDeployment plugin using notebooks
- Change Data Feed on Azure Databricks
- New trigger for each new Data Intake Process
What's new in Sidra 2022.R3¶
New DSU Ingestion module¶
This feature includes an important re-architecture of the existing Transfer Query script (used in both, Data Intake Processes ingestion as well as in the file ingestion from landing), so that this script is no longer auto-generated from .NET code for each Entity.
For this new DSU module, a structure of scripts has been designed to improve modularity, readability and testability of the DSU data ingestion process. All the scripts included as part of this DSU Ingestion module are now being installed as a plugin, so, to update any of these scripts it is no longer needed to update Sidra Core version. From a functional point of view, the new DSU Ingestion module includes the same key features of the previous Transfer Query, mainly:
- Asset registration into Sidra Core.
- Application of file reading and parsing rules as supported natively by Databricks, via a new configuration field called
readerOptions. Reading configuration parameters have been centralized in such structure, which greatly simplifies the configuration. - Data insertion/merge into Databricks tables, depending on the consolidation mode.
- Additional functions performed when reading the data, such as Data Preview tables generation and update.
The key benefits introduced by this feature are the following:
- The scripts to ingest data in the DSU do no longer need to be auto-generated from any pipeline. In case of schema or metadata changes, it is no longer necessary to re-run any pipeline to generate this script.
- The DSU Ingestion scripts are much more modularized, allowing to decouple from Sidra Core release.
- Said modularization allows for faster updates, fixes and technology evolutions.
This feature also includes the needed adaptations in all pipelines creating or executing the old Transfer Query script, namely:
- Metadata extraction pipelines for Data Intake Process connector plugins.
- Data extraction pipelines for Data Intake Process connector plugins.
- The pipelines involved in Asset ingestion via landing (e.g.
FileIngestionDatabrickspipeline).
Support for previous Transfer Query generation¶
DSU Ingestion is the expected and default module to be used when creating new Data Intake Processes in Sidra from 2022.R3 onwards. However, compatibility with prior version of the DSU Ingestion (old Transfer Query mechanism) will be simultaneously maintained for the following two Sidra versions after 2022.R3. The old Transfer Query will be referred here as legacy Transfer Query. For details on how to configure the parameters to specify whether the new DSU Ingestion module or the legacy Transfer Query script is to be used for the DSU Ingestion, please see the explanation under Breaking changes section below.
Oracle, MySQL and MariaDB connector plugins¶
During this last release period we have launched three new connector plugins for database type of sources:
- A new connector for Oracle databases.
- A new connector for MySQL databases.
- A new connector for MariaDB databases.
In previous versions, the pipeline templates already existed to connect to these sources and perform data extraction. With these new plugins, you can now configure Data Intake Processes from Sidra web wizard. The plugins above incorporate the following features:
- Ability to configure schema evolution, so that automatically new Attributes are detected in the source system tables and taken to the relevant metadata and infrastructure artifacts.
- Type translation based on the translation rules that the plugin versions dynamically provide and install.
- A much leaner release cycle to avoid hard deployment dependencies with Sidra CLI.
- Sidra-supported full and incremental load. Oracle CDC mode is still not supported in this release.
Google Analytics Universal connector plugin¶
During this last release period we have also launched a new connector plugin for Google Analytics Universal. The Sidra plugin (a.k.a. connector) for Google Analytics Universal enables seamless connection to a Google Analytics Universal account to extract metrics and dimensions reporting data.
Sidra's plugin for creating Data Intake Processes from Google Analytics Universal is responsible for extracting metrics and dimensions reporting data as offered by the Google Analytics service, and loading this data into the specified Data Storage Unit at specified intervals.
Connector modularization¶
This release includes an intensive effort in re-architecting the current catalogue of connector plugins. New versions of AzureSQL, SQLServer, Oracle, DB2 and MySQL connectors are released being compatible with this Sidra Core version. The main benefits of this re-architecture is to make the code and the deployment much more robust and modular. This will greatly optimize the efficiency and agility for developing new connectors for new data sources in upcoming Sidra releases.
PII detection and classification for Data Intake Processes¶
This PII detection feature in Sidra allows to automatically scan the ingested data against a PII classifier based on Microsoft Presidio to classify the ingested data into PII or non-PII, plus adding additional sub-categories of PII (e.g., PERSON, PHONE, etc). to the Attributes, Entities and Provider. This feature is enabled when a setting is activated to true in the additionalProperties field of the Entity or at Data Intake Process level. Whenever an Attribute, Entity or Provider are classified as PII, a tag of type System with value PII is attached to the corresponding Attribute, Entity or Provider.
Additionally:
- The sub-categories of PII are also being added to each Attribute, e.g.
Person,Email. - The union of sub-categories detected in the set of Attributes belonging to an Entity is added to the Entity.
- Provider is not tagged with PII sub-categories. It is only tagged with PII, or not tagged at all if no PII has been detected in the underlying Entities/Attributes.
The classification algorithm is run once per Data Intake Process, right after the execution of the data extraction pipeline. PII detection for files ingested via landing is still not supported in this Sidra release.
To configure which Entities to extract PII from, you can specify when the PII detection algorithm is run at two levels:
- At Entity level, there is a field
piiDetectionEnabled, inside theadditionalPropertiesof each Entity. The value isfalseby default, so you need to manually set totrueto trigger the PII detection algorithm for that specific Entity. If this value istrueat entity level, the PII detection process will be run for the Entity, no matter what the setting at Data Intake Process level is. - At Data Intake Process level, there is also a field
piiDetectionEnabled, inside theadditionalPropertiesof each Data Intake Process. The value is false by default. If the value istrue, all underlying Entities will be considered astrue, unless the value has been override manually at Entity level.
New Data Catalog global search and search for Attributes¶
The Global Search in the Data Catalog has been improved to perform more advanced queries. Now it is possible to filter by different criteria when searching for an object in the Data Catalog.
The metadata required for the search is now indexed using Azure Search capabilities, which allows for a scaled-up and more performant search.
This feature also includes new designs in the existing Data Catalog pages, so that all pages for the three-level hierarchy in the Data Catalog are consistent from the information management point of view. This means, that it is now possible to navigate from a Data Catalog landing page (very similar to the existing Providers cards view page), to a set of pages that include a left-hand navigation list of items (e.g. Providers, Entities or Attributes), and a right-hand navigation list of widgets, each including relevant detail metadata about the Provider/Entity/Attribute.
Attribute and Entity popularity are now visible from the respective Data Catalog pages. The popularity indicator represents how frequently the Entities/Attributes data is being queried by Data Products.
For more information about the Data Catalog improvements, see this documentation page.
Windows Authentication for SQL server plugin¶
Windows Authentication for SQL server plugin has been included in this release, improving the security level in the authentication for this plugin. More information can be checked in the page for the SQL server connector in Sidra.
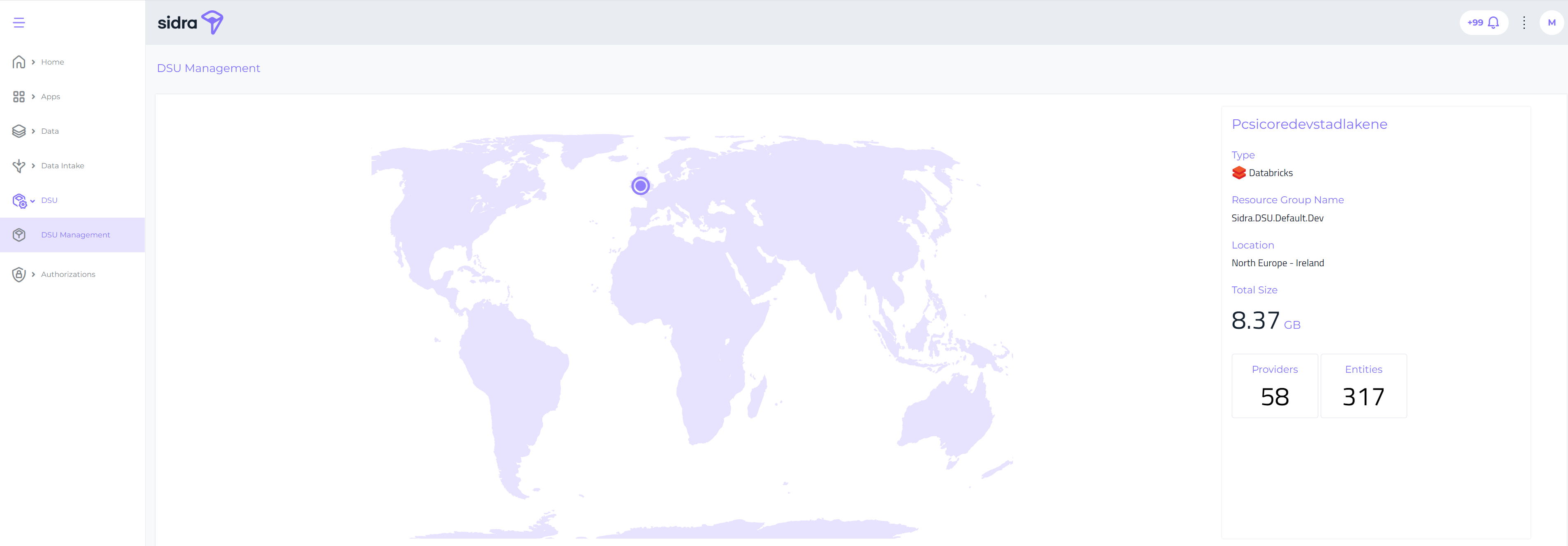
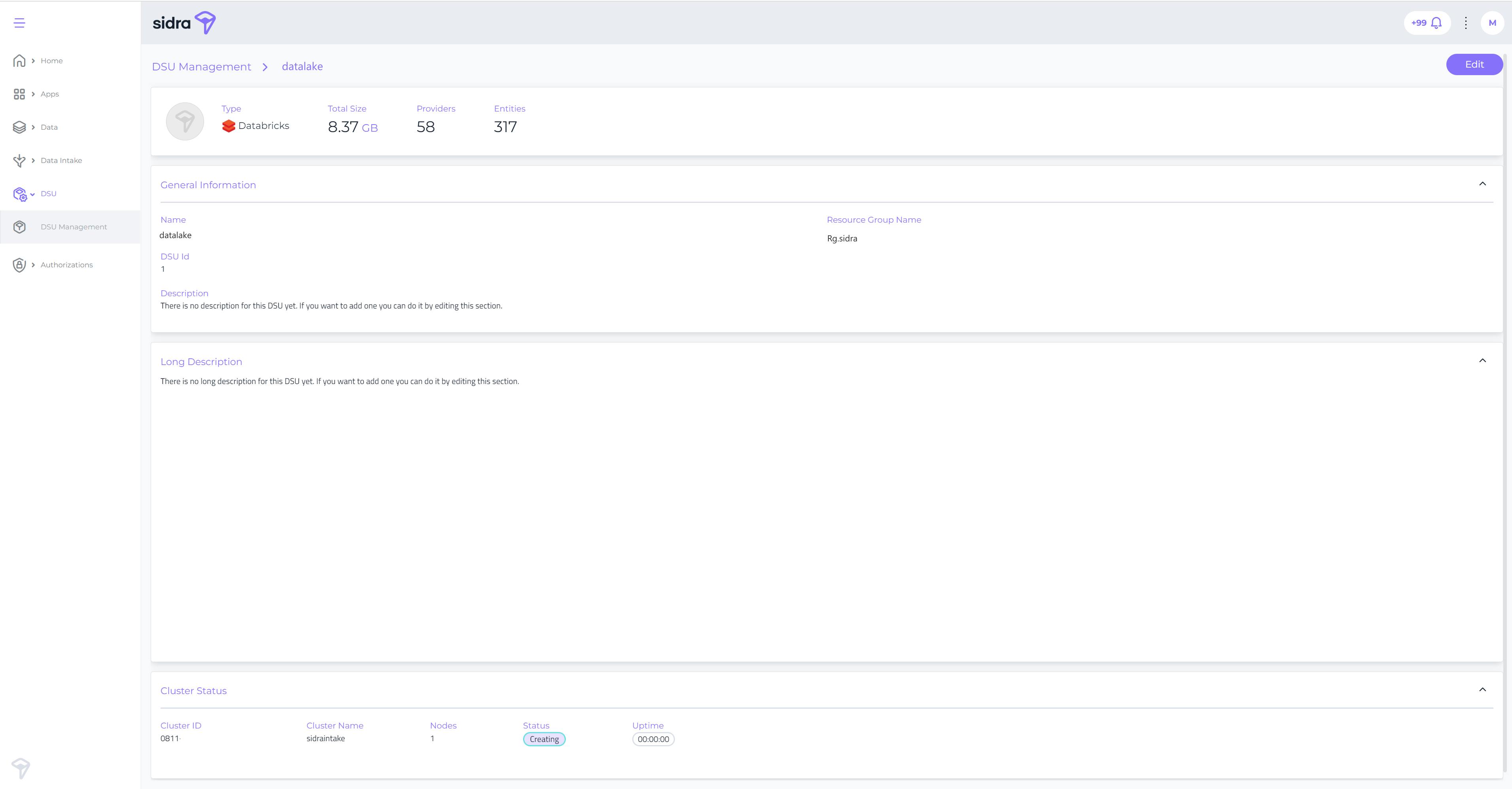
New DSU pages in Sidra web¶
This release ships a new section in Sidra web, called DSU Management. From these pages, you can see now the main information about each of the DSUs configured and deployed in the Sidra installation.
These pages show configuration and metadata-related information for the DSU, such as details for the Databricks cluster, resource groups, and number of Providers and Entities.
New scenarios for complex Excel Data Intake¶
The Data Intake flow for complex Excel files developed in previous releases has been supplemented with additional functionality that allows a much broader set of scenarios and adds robustness and ease of use in general. Please check the Excel Data Intake documentation for more information about this type of data ingestion in Sidra and all the accelerators making it possible to configure data ingestion from complex Excel files in a matter of minutes.
The improvements include support for additional scenarios, plus some utility methods for making it much easier to configure the ranges of rows and columns that make for the data tables to be ingested in Sidra. Below are the new scenarios that are supported in this Sidra version.
- Different schemas per Asset in the same Entity:
Users can now ingest some Assets belonging to the same Entity, and each Asset can have a different schema. A new table AssetAdditionalProperties has been created at Asset level to add these schemas.
- Support of cells as separate sections on tables:
Users can specify now new cells as separate sections inside the tables. To account for these new sections, the corresponding cells can be specified to be transformed as an additional column in the data table, with the name of the section as a value.
- Support for totals on tables:
When ingesting the data in Databricks, Total type of records in the Excel tables can be specified to be stored in a different JSON table in Databricks with the corresponding section value. This behaviour is automatically implemented so there is no need to add it in the AdditionalProperties field. However, it is recommendable to use some filtering syntax to avoid the loading of incorrect Total records.
- Mapping same schema and different column names:
When having two or more sheets in an Excel file that contain the exact same structure starting from the very same position, they can be specified to share the schema configured for the Entities. This scenario is robust enough to account for cases when there are some column name changes, thanks to some column mapping specification. This feature reduces greatly the need to generate multiple items in the metadata.
- Adding data from headers:
This scenario allows to relate rows when an Excel table has several rows of headers. The rows related to the headers will pivot converting into columns, so the data can be stored together. This eliminates the need to declare rigid schemas and allow for a variable number of columns.
On top of these scenarios, some utility functions have been added to ease the metadata configuration for Excel file ingestion, namely:
- API endpoints for reading and editing the
AssetAdditionalPropertiesconfiguration for an Entity. - API endpoints for editing the relationship between Entities (
DataIngestion.EntityEntity). - API endpoints for updating the Entity
ViewDefinitionvalues. - Notebooks for complex Excel file ingestion have been moved into
transferqueriesdirectory inside Databricks workspace. - Additionally, some bug fixes have been applied related to the Excel Data Intake process (see below on Fixed bugs section).
New Python client library¶
A new version of Sidra Core API Python client has been developed, so that the Sidra API methods can be called from Databricks notebooks, related to ingestion, PII detection, etc. processes. This new library is called SidraCoreApiPythonClient. Existing libraries pySidra and PythonClient will not be decommissioned until all the dependant notebooks have been migrated to the new SidraCoreApiPythonClient.
Attribute and Entity name sanitization via API¶
On declaring the metadata for CSV ingestion, users may need to use space characters inside the names of Attributes or Entities. Databricks does not allow spaces in table or column names. This feature eliminates the need for manual sanitization, by forcing the API to sanitize these entries, so that later the data ingestion does not raise an error. The space names are replaced by the _ character. Also, API calls to create an Attribute with invalid character in the name now return a 400 HTTP response, telling the invalid character that is being used in the name.
Detect and prevent Data Product record mismatch to avoid duplicates in Staging¶
Data Product pipelines for the basic SQL Data Product have been adapted to check and avoid an issue of duplicate records in the Data Product staging tables. To do this, we are now checking the number of records at metadata level (the Entity table in the Data Product), against the actual count of parquet files in the Data Product storage. If the values are not equal, the extraction is not considered correct and the pipeline now fails.
Force install a specified MaxVersion of Azure CLI¶
This item has been developed in order to better control frequent breaking changes in Sidra CLI caused by breaking changes in Az CLI releases, and to keep stability and robustness of the Sidra CLI tool. Sidra now incorporates a compatibility matrix between Sidra versions (major and minor), and Az CLI version. The present item forces to use a maximum Az CLI version before proceeding with the CLI installation of Sidra. This version is enforced as part of the pre-requirements step of Sidra CLI.
New template for PipelineDeployment plugin using notebooks¶
A new version of the plugin template used to create plugin solutions (either of type Connector or PipelineDeployment) has been created supporting the installation of Databricks notebooks, besides the installation of the typical ADF templates. This type of plugin template can be used to create plugins of type PipelineDeployment, for example, for deploying data extraction pipelines from source systems to the landing folder in Sidra. The plugin supports the configuration of a path, whereby we can specify the orchestrator notebook that calls different notebooks installed under this specified path. For more information about plugins in Sidra you can check the following documentation.
Change Data Feed on Azure Databricks¶
Change Data Feed has been included through the column GenerateDeltaTable in the table for the Entity configuration in Sidra. Now, tracking for row-level changes between versions of delta tables is available in a more optimized way.
New trigger for each new Data Intake Process¶
It is no longer needed to reuse pre-existing triggers when creating a new Data Intake Process from the Sidra web UI, since the system will create a new trigger automatically. This behaviour has been added in order to avoid more than one DIP associated to the same trigger and to have the possibility that users can individually start or stop the trigger for each DIP.
Issues fixed in Sidra 2022.R3¶
Sidra's team is constantly working on improving the product stability, so is that, here it is included the following list which contains the more relevant bugs fixed and improvements developed as part of this new release:
- Fixed an issue in Sidra web dashboard page, where the Services component was missing Services description. #142692
- Reviewed text formatting for contextual help in Sharepoint plugin in Sidra connectors wizard. #143067
- Provided a fix to an issue in the Provider detail view regarding Provider image edition. #144576
- Fixed an issue where the DIP view in Sidra web was not responsive to the window. #143087
- Solved multiple cosmetic issues with element paddings to make them more consistent, across Sidra web pages. #142859
- Fixed a validation error when using mandatory dependent fields in the connector's wizard. #125684
- Reviewed an interaction glitch in connector plugins to display conditional form elements. #126156
- Fixed an issue in the Data Products UI page while searching for Data Products. #130998
- Solved a cosmetic issue in Data Intake connectors gallery when the navigation button was expanded. #144055
- Solved an issue with validation of the Object Restriction list in MySQL plugin, compatible with 1.12.2 version. #142448
- Fixed an issue in Entities list page in Sidra web, where the Entities graph scale and order was inconsistent with the actual data. #145621
- Solved an issue in connector plugins, where the method to get the latest version was not returning the latest version due to a version comparison issue. #144575
- Fixed an issue in Sharepoint connector plugin, when the Sharepoint URL had trailing slash, by adding regular expression validation. #145956
- Fixed a visual problem in the Entities list page in Sidra web, where the tooltips for the Entities names is not displayed correctly. #146600
- Fixed an issue where Assets belonging to Entities with incremental load were throwing exceptions due to null
DestinationPathof the Asset. #143355 - Fixed translations file for Spanish and English versions in Sidra web. #142855
- Solved an issue with validation of the Object Restriction list in MySQL plugin, compatible with 1.12.2 version. #142448
- Solved an issue with the MySQL plugin compatible with 1.12.2, which was accidentally removing DIP when
validateis used beforeexecute. #147454 - Reviewed and fixed skeleton alignment issues across different Sidra web pages. #142866
- Reviewed and fixed several notification styling elements in Sidra web. #142870
- Fixed an issue in Attributes detail view when editing the Description field and the cancel button is pressed. #137823
- Fixed casing of resource group parameter at Install command, also normalizes the naming between all the commands to match (--resourceGroupName). #147494
- Fixed an issue when editing the details of the Data Product, where the data was updated with a big delay. #147772
- Fixed a problem with notifications text alignment in notification widget in Sidra web. #142864
- Reviewed a cosmetic issue in cluster status section in Dashboard in Sidra web. #142868
- Fixed an issue caused by a breaking change in az cli version 2.38, that was causing 'az ad app show' and 'az ad sp show' command fail at
CreateAADApplicationfunction. #147962 - Fixed a glitch when handling date intervals for Logs searching in Sidra web. #142686
- Solved an issue with validation error message in Providers step in plugins wizard in Sidra web. #119266
- Solved an issue with validation error in plugin wizards not appearing until the wizard step is changed. #121025
- Fixed a security issue in Connector plugins, to avoid storing passwords as part of the JSON for the last execution of a Data Intake Process in Sidra Core metadata DB. #147938
- Fix Azure CLI breaking changes due to deprecation of AAD Graph, the AAD Graph API will be replaced by MS Graph API. #148348
- Solved an issue about claims not being added in IdentityServer for Data Product API. #150691
- Fixed 'az cli' breaking changes regards rename of parameters in 'az ad app update' command, regarding some breaking changes at version 2.37 of Az CLI. #147742
- Solved an issue removing artifacts in the validation of MySQL plugin. #149042
- Fixed a problem in MySQL and Oracle pipeline templates that was preventing from performing publications from ADF UI. #149043
- Fixed a bug with complex Excel Data Intake, where Databricks notebook was throwing an error in
create_entity_viewscall. #146443 - Solved an issue deploying/removing pipelines with dependencies from ADF. #148807
- Solved an issue executing Sidra CLI with the option to enable Power BI reports. #147310
- Fixed an problem when Power BI option in CLI was not creating service principal when the scopes parameter was not defined. #147807
- Fixed an issue with DB2 plugin, where the metadata extraction pipeline had some hardcoded values for objects to extract. #148921
- Fixed an issue where the
ExcelDataIntakewas not present under the expected path /Shared/transferqueries/. #146439 - Solved an issue with duplicated records in staging tables with same
IdAsset. #136592 - Fixed a compatibility issue with MySQL plugin and the orchestrator pipeline definition. #149159
- Added a fix in the Identity Server to allow the creation of external users with apostrophes in their email. #150165
- Fixed an issue in CLI prerequisites verify to warn the user that a non-supported AZ version is installed. #148939
- Fixed a bug that caused the non-execution of schema evolution due to an issue in updating the deployed date of a pipeline. #148958
- Solved an issue in Sidra web, Authorizations Apps section, where the validation message when creating a role was wrong. #144580
- Solved a problem when adding tags to an Attribute in Sidra web. #150719
- Fixed an issue with type translations in Azure SQL plugin for SQL timestamp field types. #149282
- Fixed an error in Sidra web authorizations where the error toast messages when performing editions on Delegation were incorrect. #123466
- Fixed an issue when Sync webjob was allowing duplicate Attributes when Schema evolution is used in Sidra Core. #148662
- Solved an issue with the re-creation of the Databricks token after removing an installation, where the new token secret was not being updated correctly. #149956
- Solved an issue with the AAD App secrets not being updated after a first install aadapplication. #149951
- Fixed an issue with wrong
TypeTranslationsbeing used for some types in MySQL plugin, compatible with version 1.12.2. #148433 - Reviewed an issue in Data Product stored procedure that fails is some Entities are disabled. #146521
- Fixed some cosmetic issues in Provides list view in the Data Catalog landing page in Sidra web. #151988
- Fix allowed values of Databricks workspace tier to be specified when configuring deployments. #149815
- Fixed a misleading error in plugin validation message when Integration Runtime was not installed. #147862
- Fixed an issue with Sidra Core template installation, which was not including SidraVersion in Sidra CLI prerequisites setup command. #151877
- Solved a bug in Sidra CLI install aadapplications command, which was upgrading to the latest version of CLI (not compatible). #151705
- Fixed an issue with SignalR connections from the Core API when reporting pipeline failures, which was filling up errors on console. #149704
- Solved an issue where the Data Products deployment was failing due to an incorrect reference to Sidra PlainConcepts.Sidra.App.Api.WebApi. #151518
- Fixed an issue in intake pipelines with incremental loads configured without use change tracking. #135551
- Solved an issue with
RunIndexMaintenancepipeline failing when the index optimization tasks were pointing to the wrong Linked Service. #152379 - Solved a bug when upgrading Sidra version through CLI due to a NETSDK1152 error when deploying pipeline execution. #152681
- Fixed an issue upgrading a Data Product pipeline template
DSUExtractionStorageAndSQLPipelineTemplateto 1.12.2 due to an incorrect loop. #153505 - Fixed an issue about pipelineTemplates names duplications. #154285
- Fixed an issue retrieving a mySQL data source schema. #153935
- Solved an issue when deploying a new Sidra installation about an error for the creation of the system DIP for Logging. #154888
- Fixed an issue about discrepancy between different endpoints for popularity value shown in the Sidra Web. #154134
- Fixed an issue when schema evolution is activated, and the Entity is configured as Incremental Load using a specific Attribute. #153952
- Fixed an issue that avoids showing the description of a Data Product in the UI. #153814
- Fixed an issue with the Python client generation due to a breaking change in the newest packages versions. #143634
- Fixed an issue in SQL and Databricks Data Product where it was required set values for optional parameters. #143622
- Fixed an issue with type translations in Azure SQL and SQL Sever for SQL timestamp. #143705
- Fixed an issue with Azure SQL and SQL Server type translations for XML types. #143708
- Solved an issue in Sidra Core API where creating
EntityPipelinerelationship was failing if the relationship already existed. #143733
Breaking Changes in Sidra 2022.R3¶
New DSU Ingestion module¶
Description¶
DSU Ingestion is the expected and default module to be used when creating new Data Intake Processes in Sidra from 2022.R3 onwards. However, compatibility with prior version of the DSU Ingestion (old Transfer Query mechanism) will be provided for the following two Sidra versions after 2022.R3. The old Transfer Query will be referred here as legacy Transfer Query. By default, as mentioned before, the new DSU Ingestion script will be executed. Nevertheless, a new configuration parameter needs to be added in the
additionalPropertiesfield of the Entity table, to specify whether to run the legacy Transfer Query or not:UseLegacyTransferQuery(value set totrue). For using the legacy Transfer Query, you need to check the Required actions as there are some breaking changes.Required Action¶
To give some context, there are a couple of configuration parameters at Entity level (inside
additionalPropertiesfield), to signal the usage of, on one side, a custom Transfer Query; or, on the other side, the legacy Transfer Query or the new DSU Ingestion module. These parameters are the following:
TransferQueryfield: without changes in this release, this parameter needs to be included manually inadditionalPropertiesfield in the Entity. It specifies the path to the custom script for the ingestion. For example, this field is usually used for the specific script path for ingesting Complex Excel Data Intake.UseLegacyTransferQueryfield: new field in 2022.R3 release, this parameter needs to be included manually inadditionalPropertiesfield in the Entity. It specifies whether we want to use the legacy Transfer Query, autogenerating it whentrue.Below is the description of the behaviour for configuring which mechanism to use for Data Intake Processes (ingestion configured using connector plugins):
- The default behaviour is to use the new DSU Ingestion when
UseLegacyTransferQueryis not added and set totrue. Therefore, Data Intake Processes created with plugin versions compatible with 2022.R3 version of Sidra Core will create pipelines that will use the new DSU Ingestion module.- Existing running pipelines created as part of Data Intake Processes before Sidra Core version 2022.R3, will continue to use legacy auto-generated Transfer Query. A migration process will need to be performed to replace the pipelines by the new pipelines that use the new DSU Ingestion module by default. In this case, we do not require the parameter
UseLegacyTransferQuery.Below is a description of the behaviour for configuring which mechanism to use for ingestion via landing:
For the ingestion via landing, as this is an artifact that gets created and deployed in a generic way with Sidra Core installation, some explicit manual action is required after upgrading to Sidra 2022.R3:
- To use the new DSU Ingestion, you do not need to define and update any of the parameters
TransferQueryorUseLegacyTransferQuery, as their default values will resort to using the new DSU Ingestion module.- To continue using the legacy Transfer Query, you need to explicitly define the field
additionalProperties.UseLegacyTransferQueryand set it totrue. The pipeline internally will calculate the path to the legacy Transfer Query when it detectsadditionalProperties.UseLegacyTransferQueryis set totrue.- A third scenario is when you want to use a new (custom) Transfer Query (for example, for complex Excel File ingestion, we have a dedicated custom Transfer Query). In this case, the
additionalProperties.TransferQueryfield should be defined with the path to the custom Transfer Query. The parameterUseLegacytransferQuerywill not be considered since theadditionalProperties.TransferQueryprevails over it.For more information about the
additionalProperties.TransferQueryandadditionalProperties.UseLegacyTransferQuery, please check this documentation page.
New Azure Search module in Sidra Core¶
Description¶
As part of the new Global search for the Data Catalog in Sidra web, we have incorporated an Azure Search service to the Sidra Core resource group. This is a separate service to the Azure Search service used inside the DSU resource group.
Required Action¶
This does not require any required action when deploying Sidra through the CLI tool. There is a parameter
reCreateAzureSearchthat is by default set tofalsein the Deploy command of the CLI tool. If you set this totrue, the Azure Search service will be completely re-created during deployment time, which means that all the existing indexes for metadata will be removed and a new indexing process from scratch will need to run to allow for a full reindexing of all the related metadata tables (Providers, Entities, Assets, Tags and other related tables).For a conceptual view, check this page.
New Sidra command on the CLI tool¶
Description¶
A new Sidra CLI command
deploy privatewebappshas been added which objective is to include the new features for deploying private endpoints and custom domains.Required Action¶
This command is optional, thus it is not necessary to run it from a normal Sidra installation. The only different aspect regarding a normal installation is the automatic addition of a new variable in Sidra Common DevOps var group:
privateWebAppsVnet. Taking the value of this variable, the DevOps pipeline decides which deployment perform in runtime. If the var is empty, a normal deployment will be run, if not, it will try to deploy private endpoints. Please, refer to the documentation page for more information.
Commands modified in CLI tool¶
Description¶
The parameters of
LlagarACRHostandLlagarACRUserare placed now in the Sidra.exeinstall aadapplicationscommand, instead of indeploycommand as before.Required Action¶
No action is required. For more information, check the
installcommand anddeploycommand pages.
New SQL function for Data Products¶
Description¶
The stored procedure
GetPendingIdAssetByOrderis available to be called, under specific circumstances, by the Orchestrator stored procedure activity from the Data Product ADF pipelines. Due to several potential issues, this stored procedure has been deprecated, and a new SQL function called[Sidra].[GetNextPendingIdAsset]is recommended to be used. These are the potential issues with this old stored procedure that have been corrected in the new function: - First, the return value of the stored procedureGetPendingIdAssetByOrderreturns theIdAssetas an INTEGER return value. This can trigger issues in the future, when a big number of Assets are being tracked. This has been fixed in the new function by specifying a return value of BIGINT. - Second, the old stored procedureGetPendingIdAssetByOrderdoes not take into account any custom naming on the Staging tables. This has been fixed in the new function by adding an additional parameter@SchemaName, which, if null, will take the valueStaging. - Finally, the old stored procedureGetPendingIdAssetByOrderis usingProviderNameinstead ofDatabaseName, but the convention we use to create the staging tables isDatabaseName. This has been changed in the new function to useDatabaseName. Normally both are equal, and if you have been using the convention, it should not be a problem.Required Action¶
The old stored procedure
GetPendingIdAssetByOrderhas not been removed from the Data Product persistence project, to avoid immediate breaking changes. However, it is highly recommended that new Data Product pipelines call the new function instead of the deprecated one. Also, it is highly recommended that the call to the old stored procedure is changed to use the new function,[Sidra].[GetNextPendingIdAsset].
Coming soon...¶
This 2022.R3 release represents an important step towards making the existing pipelines and data ingestion robust enough to handle new scenarios.
As part of the next release, we are planning to work on the Data Intake Process configuration update and version upgrade from Sidra web. This will greatly reduce the operational overhead related to Sidra version updates. In addition, we will release significant improvements on the synchronization mechanism between DSU and Data Products. We are also planning on extending Sidra web capabilities, by providing a further operational view on Data Intake Processes.
Feedback¶
We would love to hear from you! You can make a product suggestion, report an issue, ask questions, find answers and propose new features by reaching out to us in [email protected].