Sidra Data Platform (version 2021.R2: Glamorous Goldspur)¶
released on Sep 29, 2021
This release comes with a lot of improvement features on several key modules of Sidra, especially on the data ingestion and the ML serving space. The data intake improvements have also been taken to the UI connectors (plugin) model, so the new versions of the connectors include multiple performance and functional improvements.
The plugin approach used for connectors (configuration of new data intake processes) has also been adapted to the Data Product space. This way, with this model, any new Data Product in Sidra that is developed following this plugin package approach can be easily created and deployed from a web UI.
On top of that, this release comes with important features around the operability of the platform, both from the web perspective, but also from the perspective of other operational tools, like the automation of API services monitoring and restarts.
With this release, we are also pleased to announce our new Sidra ideas portal, where you can have a place to share and vote ideas for Sidra.
Sidra 2021.R2 Release Overview¶
This release comes with very significant features and improvements, some of which represent a big architectural change that is the cornerstone of the new Sidra:
- Data intake functional and performance improvements
- Data Products UI assistant from Web and Data Products detail page
- Multiple DSUs installation process
- Plugin visibility management
- Type Translations versioning and handling by plugins
- Optimizations for handling tables in Databricks
- ML Model Serving updates
- Oracle pipeline v1
- Inclusion and exclusion modes in metadata extraction
- DB2 connector plugin
- API automation account for health monitoring
- SQL Server metadata extraction for multiple databases
- Sidra CLI improvements
- Sidra Provider
- Attributes popularity
- API endpoint for EntityDeltaLoad
- Sidra Ideas portal
What's new in Sidra 2021.R2¶
Data intake functional and performance improvements¶
A big part of engineering effort in this release has been dedicated to review and update important functional and performance enhancements on data intake pipelines. These new features have been introduced in order to support certain new scenarios, as well as to substantially improve performance of the data intake processes.
Next is a list with all the updates included in this feature:
-
Support automatic reload on Change Tracking expiration
The data ingestion incremental load process for SQL Server can use SQL Server native change tracking capabilities or use the Sidra-provided mechanism to track changes. In the case of using Change Tracking, Sidra now supports specific scenarios related to Change Tracking expiration. Before this change, when Change Tracking expired, tables in Sidra were marked as
NeedReloadflag toTrue. However, this was not enough to force a reload until the fieldEnableReloadwas set to 1 in theEntityDeltaLoadtable. This feature now includes an improvement by which a newAutomaticReloadproperty is used and populated in the AdditionalProperties Entity field. This way, when this fieldAutomaticReloadis true, andNeedReloadis true, a condition is triggered to reload the pipeline, no matter the value ofEnableReload.You can see more information about these fields in the EntityDeltaLoad and SQL Server incremental load mechanism documentation pages.
-
Prevent access token from expiring in metadata extraction pipelines
Metadata extraction pipeline templates have been amended to prevent the Identity Server access token from expiring. This is especially important when there is a big amount of data to be managed in the pipelines for metadata extraction (for example, for the database metadata extraction pipelines).
-
Handle truncate behaviour in source systems when not followed by new inserts
When a table is truncated in the source, Change Tracking expires, and the table will be marked for reload. In this scenario, the table will be truncated in the data lake before inserting or merging the new data. Before this change, this worked fine if there was no new data, but if the table was truncated and no new data was inserted, the truncate on the data lake did not happen and the table kept the old data. Sidra now handles this scenario better, by ensuring that truncating a table from the source system is successfully reflected on all cases.
-
Iteration performance improvements in Change Tracking mode
The incremental load with Change Tracking logic has been optimized, so the system does not have to iterate through all the tables, but only through the ones that have the actual changes. This has rendered a substantial performance improvement and cut down pipeline execution times substantially.
-
Make dummy assets optional
Dummy assets or empty assets are an internal construct used in Sidra when there are no changes in the source data during incremental loads. Dummy assets are needed to enable synchronization with the downstream Data Products, which are configured to launch data synchronization pipelines with Sidra Core when all Assets have been created. Via these empty Assets it is signalled when an actual finished data intake process of the Entity happens. This enhancement makes the creation of this dummy Assets optional (and set to disabled by default), to adapt for scenarios where the periodicity of data intake into the data lake may be much more frequent than the periodicity required at the Data Product end. This means that, for those cases where dummy Assets approach was being followed, it will need to be explicitly configured as active in future deployments.
Data Products UI assistant from Web and Data Products detail page¶
In the previous release of Sidra, 2021.R1, data connectors UI feature was launched to simplify the configuration of new data intake processes via Sidra Web. Although using the term connectors to refer to the different programs to connect to the data source systems (e.g. SQL Server, Azure SQL database), internally such programs are packaged in a plugin model. For creating and configuring data intake processes, we use plugins of type connector. Such plugins are code assemblies that get downloaded, installed, and executed from the Web UI.
A very important advantage of plugins is that their release lifecycle can be decoupled from Sidra main releases life-cycle, which increases delivery speed for new plugins and reduces dependencies. You can see more details about the plugin approach in Sidra connectors documentation. With 2021.R2 the whole plugin management and architecture has been adapted to allow the deployment of Data Products from the Web. In this case the plugins used are of type Data Product.
This is a major achievement of this release. Along subsequent versions of Sidra, we plan to announce and release new plugins of type Data Product. We plan to migrate existing Data Product templates with this new plugin model, so that the deployment (from a given template) of a Sidra Data Product can be performed just by filling out a set of UI wizard steps. The same approach is ready to be followed as well for implementing future new customer Sidra Data Products.
In addition to this, Sidra Web now incorporates a Data Product detail page that exposes the metadata information about Data Products. Clicking on each Data Product, a Data Product detail page is opened, which displays metadata fields like the Data Catalog for Providers and Entities: short description, business owner and a detailed description field allowing markdown edition.
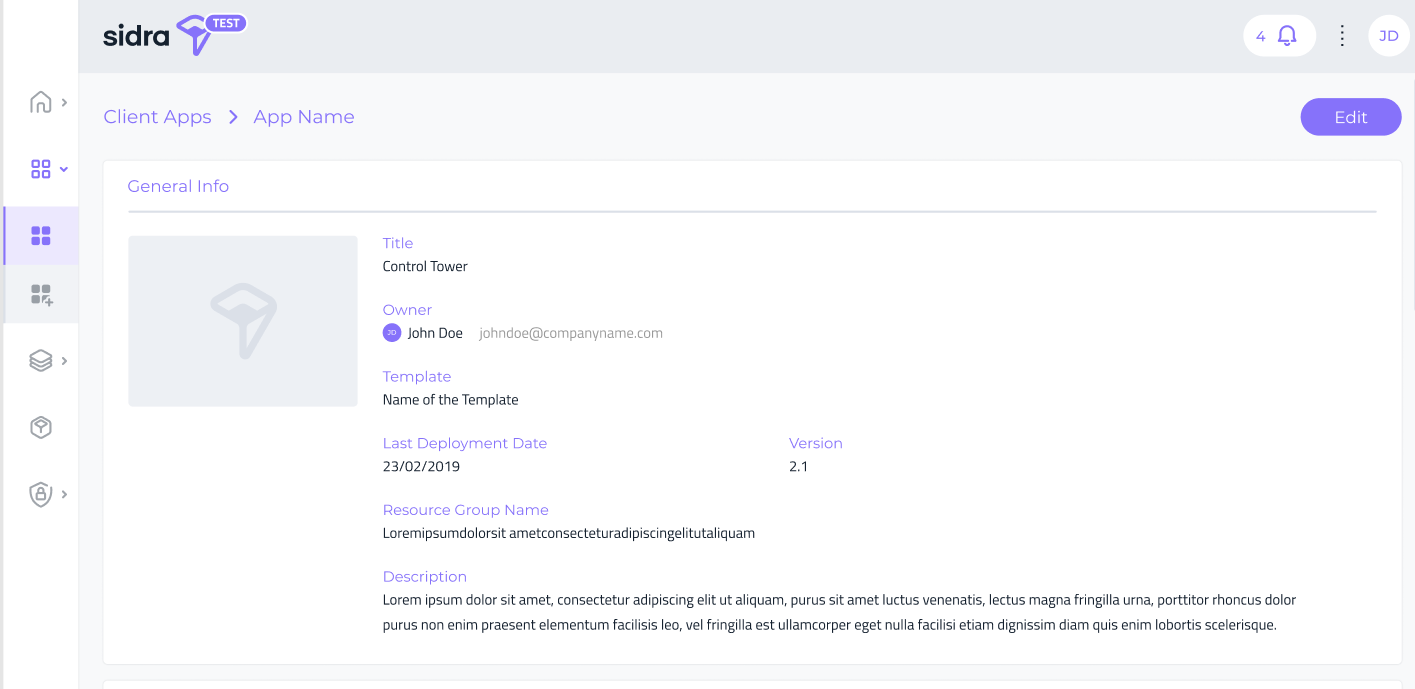
This view will be the entry point towards adding, in subsequent releases, more operational details and actions on Data Products.
Multiple DSUs installation process¶
Sidra architecture relies on the concept of Data Storage Unit (DSU) as the atomic infrastructure unit for data processing (data intake, data storage, data transformation, data indexing and data ingestion) in Sidra. Each Data Storage Unit allows separation of concerns and even regional data segregation if needed.
After releasing Sidra CLI tool for installation and deployment of Sidra, there was a pending requirement to migrate the new deployment process to separately being able to install a second or subsequent DSUs. This feature incorporates a specific deployment script and process for installing additional DSUs on top of the default DSU which comes with any Sidra installation. This feature is subject to the availability of dependant Data Storage Unit Azure services in each region, and this includes Databricks service regional availability.
Plugin visibility management¶
This feature allows to decouple plugin development and release cycles, both for connectors and for Data Products, by managing the visibility of any plugin and plugin version at each customer and Sidra installation level. Through this feature, it is now possible fo customers to limit the visibility of plugins and plugin versions to certain Sidra installations. This enables scenarios of early testing and validation of new plugins being developed.
Type Translations versioning and handling by plugins¶
The TypeTranslation table stores type mapping and transformation rules for the different stages of the Attributes processing when data sources are configured and ingested in Sidra. You can see more information about these tables in Data ingestion documentation and About Sidra connectors pages.
The use of such table has been extended to host all types of type mapping and transformation rules between database source systems, ADF and Databricks. Each plugin now handles the configuration and versioning of a set of type translation rules. These type translation rules are then applied during the data extraction and ingestion processes.
Each plugin persists the needed data types translations and rules when being installed. The responsibility to populate this TypeTranslation table also lies now on each specific plugin, instead of being centralized in Sidra Core.
This means that the different type mappings for each connector plugin are now completely decoupled from Sidra Core release process and tied solely to the corresponding plugin release process.
Optimizations for handling tables in Databricks¶
As part of the operational hardening of the platform, we have incorporated a set of enhancements related to creating and handling Databricks tables in certain scenarios. These are the set of changes included as part of this optimization:
- We have incorporated a safeguard to prevent names longer than 128 characters in temporary tables when performing metadata extraction.
- We also have performed renaming of Databricks tables to avoid name conflicts when there is an overlap of table names across different sources configured logically to belong to the same Provider.
- The new naming convention uses this format:
<database>_<schema>_<table name> - Additionally, we have incorporated a deduplication rule for the names of the Attributes in Databricks. We detected that some client sources may have multiple field names that are even single, non-supported characters in Databricks, e.g.,
#,*, etc. These names are transformed into the_character when moving to Databricks. This means that many of these Attributes may end up having the same name. In order to avoid this, the change consists of appending a number suffix to the names of the columns in Databricks, e.g.,_1,_2, etc., so there is no duplication of column names.
Databricks version update¶
Databricks runtime version in Sidra has been updated to 8.3. This comes with interesting updates and features, like Python 3.8, faster cluster startup times, many performance improvements and as JSON operators in SQL, among others.
ML Model Serving updates¶
We have performed an extensive review on Sidra's ML Model serving framework and capabilities, to adapt to the fast changing landscape and technical evolution of the key services underneath this module. These are the main updates performed as part of this review:
- Updated Python Version to 8.3.3.
- Updated MLFlow to 1.18.
- Updated AzureML components to 1.32.
- Updated the ML Deployment notebooks to accommodate to the breaking changes in AzureML and MLFlow updates.
- Updated the ML tutorial and code examples.
Oracle pipeline v1¶
We have implemented our first version of an Oracle pipeline template following Sidra design guidelines. This data intake process has not been implemented yet as a plugin of type connector, but this is planned for the next release of Sidra. The main characteristics of this Oracle pipeline are the following ones:
- The source system version to be supported is 19.X (latest).
- A metadata extraction pipeline has been implemented in order to get schema for source system tables and automatically create the needed Sidra metadata structures (Entities and Attributes).
- This pipeline supports both initial load and incremental load mechanisms. For incremental load, the pipeline relies on Sidra-backed EntityDeltaLoad table. Native change tracking mechanisms from Oracle are expected to be implemented in further versions of this pipeline/plugin.
- Type translations between source systems and Sidra data lake is versioned and and handled by plugin-created tables. Plugin installation now adds the needed type translations for metadata and data ingestion process. See new feature for Type Translations above.
Inclusion and exclusion modes in metadata extraction¶
Data intake pipelines for database source systems (e.g. SQL, DB2) included a tables exclusion parameter in order to configure a list of objects to exclude from the metadata extraction pipeline. With this Sidra release, we have incorporated an enhanced object selection mechanism, through which users can choose a list of objects to include, or a list of objects to exclude. By default, inclusion mode with all objects is configured. This change has been taken to existing database pipelines and plugins: SQL Server, Azure SQL, DB2, plus the Oracle pipelines. Internally, objects to include or exclude are persisted on the LoadRestrictionObject tables in Sidra Core database. You can see documentation on LoadRestrictions and About connectors feature documentation.
DB2 connector plugin¶
Sidra now incorporates support for DB2 in the connectors framework model. This allows to set up a data intake process from DB2 database source systems just by following a few-steps configuration wizard. This version of the plugin comes with Sidra-backed incremental load mechanism.
API automation account for health monitoring¶
Sidra incorporates an out of the box capability to run different operational runbooks to automate the periodic health monitoring of API services and attempt automatic restart in case they are down. This is achieved via Azure automation account implementation.
SQL Server metadata extraction for multiple databases¶
This release comes with a new version of the SQL Server metadata extraction pipeline, which has also been released as a new version of the SQL Server connector plugin. This version allows to configure the metadata extraction from multiple databases inside an SQL Server at once, so they logically link in Sidra to the same Provider.
This change has been done in the metadata extraction pipeline of the SQL Server plugin. Now, in the SQL Server plugin, if a database is not specified, the default database is be taken as master, which now forces to loop through the whole list of databases inside the same SQL Server and extract metadata from all of them.
This greatly simplifies and streamlines the process of data intake, as now we can configure a data source where there is a big number of different databases sitting in an SQL Server with just a few steps.
Sidra CLI improvements¶
Sidra CLI tool for installations and updates has been reviewed to ensure all commands are idempotent by default. This means that the different commands can be executed several times without needing to manually remove any data from Azure. This improvement minimizes the operational issues that can happen when there is any unexpected problem when running the commands. More specifically, the aadaplications command has been made idempotent, ensuring that all AAD applications are removed automatically before re-running the command, with no manual intervention required.
Sidra operational Provider¶
Sidra now incorporates an internal Provider containing relevant data sources originating internally in Sidra from tracing and operational modules.
The first version of this internal Sidra Provider includes the Log database in Sidra Core. Log database stores a copy of the logs (traces) of the platform , by applying a set of filters. There are several tables where the logs are located. This Provider improves performance of Log database, by moving the older traces to the data lake (from which it can be queried and explored through Databricks). This allows to optimize the Log database by reducing retention period in the database to the last 30 days. The full Log history is available in Databricks tables.
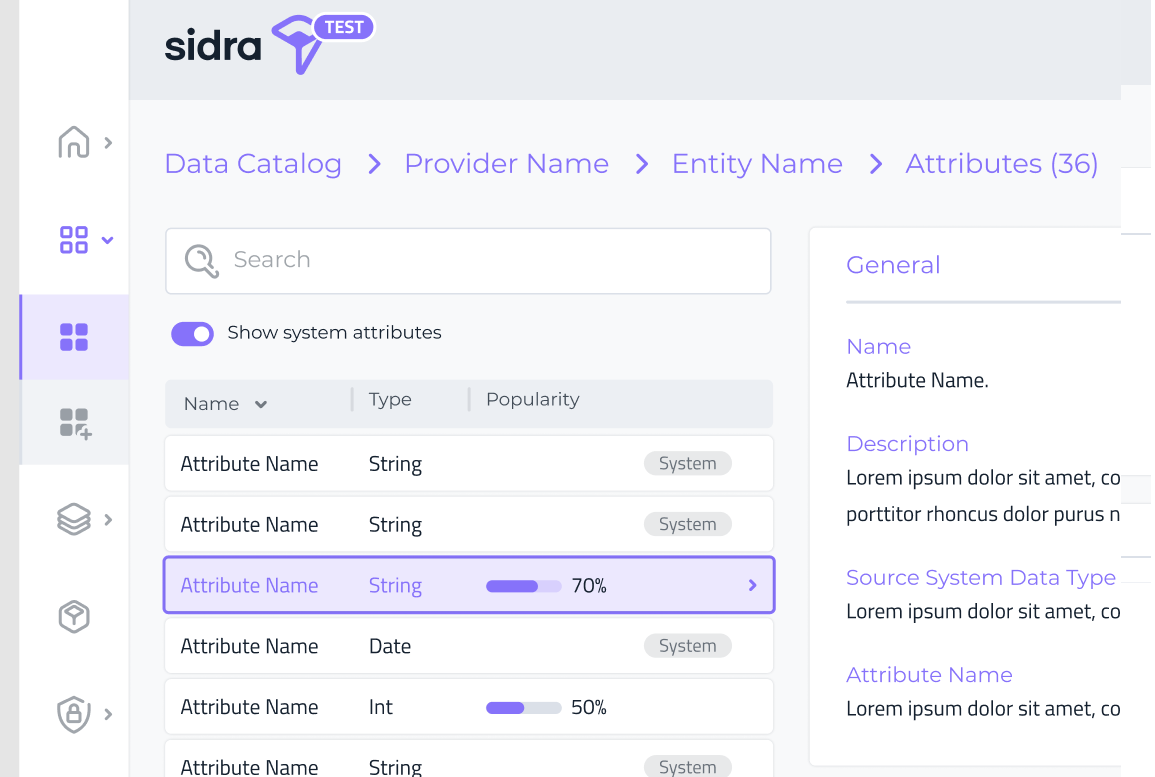
Attributes popularity¶
Sidra Data Catalog now includes the ability to see the popularity for all Attributes in the Attribute list and details page. Before this feature, just the top three Attributes popularity was displayed as a sample, in the Entity details page.
API endpoint for EntityDeltaLoad¶
Sidra API now incorporates API endpoints to serve create, read, update and delete operations on EntityDeltaLoad table. This table is a key piece in Sidra metadata DataIngestion schema tables. This table fully tracks the needed data for managing incremental loads from source systems, which is independent of any native supported change tracking mechanisms.
See Sidra documentation for DataIngestion tables for more details about structure and usage of this table.
Issues fixed in Sidra 2021.R2¶
This has been a significant effort accomplished in terms of product stabilization and bug fixing, with some of the more relevant bugs and improvements listed below:
- Solved an issue in Balea API by including sanitization of Balea app name. #118550
- Fixed an error in the unstructured data process, which did not work when using the
indexlandingcontainer folder. #110186 - Added a fix in Data Products deployment PowerShell script in order to use
azmodule. #115907 - Fixed an issue in rollback of connectors plugin, whereby Provider entry was not properly deleted. #116330
- Solved an issue with form navigation in connectors UI wizard through tabs key. #116482
- Fixed a UI issue in Authorizations - Users to render the full tree with adequate scroll. #116617
- Fixed a defect deploying a new version of a plugin. #117662
- Fixed an error due to MySQL to SQL conversion incorrect syntax. #117075
- The data type of
MaxLenin Attribute table for Data Products has been changed toINTto reflect the changes in Core. #117806 - Fixed an issue after update
Microsoft.Azure.Management.ResourceManagerpackage. #117890 - Solved a missing configuration for the
DataStorageUnitmetadata in Sidra API. #118218 - Fixed a problem when calling
PATCHmethods using the functionWebAPIConsumeAPI, becausePATCHmethods were not included in the valid set for the parameter API method. #118002 - Fixed a frontend issue when changing steps in the connectors wizard under specific circumstances. #115904
- Fixed an issue in
AssetNameby extending length to contain 500 characters. #118617 - Added a missing relationship between the MySQL pipeline and the dataset template that was preventing deployment to complete successfully. #117533
- Solved a performance issue in the call to
ExtractTypeInferenceby adding retries and changing response status code. #117954 - Fixed an issue on a package for the ingestion of documents from Azure Search. #118332
- Fixed a defect using
POSTandPUTAPI methods to interact with Entity, that was preventing the creation/update of theSourcePathproperty. #118178 - Fixed an issue in Connectors web page that showed an incorrect validation check. #118985
- Fixed a defect that cause the information of the cluster status in Sidra Web not to be shown properly. #119006
- Solved an issue that cause an error in the job for the Operational Dashboard. #119008
- Fixed a defect extracting the metadata for columns with Geography data type in TSQL with
Geographytype column. #119009 - Solved an issue in
DatabricksSetupscript that was throwing error in a clean 1.9 installation. #118881 - Fixed an issue with Azure DevOps service account creation step, by replacing an az command. #118874
- Fixed a problem retrieving the latest version of a connector from Llagar. #119139
- Solved a problem with triggers in ADF to force start if it has at least one pipeline associated. #119497
- Fixed an issue calculating the max length for a field defined as
varbinary(max). #119500 - Fixed an issue in Dashboard page that prevents to load the Data Intake information. #118988
- Solved a problem where data extraction pipeline was not rolled-back when a Provider using a custom trigger failed on metadata extraction. #119761
- Fixed the rollback implementation when there is an error in metadata extraction and using custom triggers. #119760
- Fixed an issue where data extraction pipeline creation was cancelled but no notifications sent when using a custom trigger. #119073
- Solved a defect where association to triggers was not removed when pipeline is deleted from plugin code. #119613
- Fixed an issue associating pipelines to existing triggers in connectors model. #119776
- Amended a frontend issue that caused the creating of a trigger with an incorrect date. #119774
- Fixed an issue in connectors when validating dates for new trigger creation when creating pipelines. #119370
- Solved an issue with trigger interval field in connectors creation when using a new trigger. #119387
- Fixed a defect when validating names of Providers in connector plugin execution. #119885
- Fixed a mis-configuration in the release pipeline that prevents start the API correctly after a deployment. #119133
- Solved an issue where some keys were not being registered properly in KeyVault because secrets were decoded unnecessarily. #119479
- Fixed frontend experience in Connectors page to prevent a message is shown several times. #119779
- Fixed an issue in Data Product templates in order to sanitize the application name. #120060
- Fixed an issue when PrepareDataLoad pipeline was failing due to a 401 error using the internal API. #120331
- Solved a frontend experience issue when the Confirm button could be clicked more than once for the same plugin execution operation
- Changed
DataLabApptemplate parameter name to indicate preferred Azure PowerShell version. #120878 - Increased max length for the source and destination asset paths in metadata DB. #120071
- Fixed a rendering issue of contextual help icons in connectors wizard. #120384
- Fixed a cosmetic defect with
Sourcefield being overflowed in Data Catalog widget. #121204 - Added a solution to allow for multiple files to be put in a folder to customize IS. #121533
- Solved a defect with Knowledge Store tables not being stored on Azure Databricks when using combination of indexes using
assetIDas index key. Now the output of the knowledge store leaves the full content in a filter whose name is theassetID. #123004 - Added support for backlashes in server route in SQL Server plugin. #120270
- Fixed issue in
ChangeTrackingBatchActivity, when the source fields are defined with certain binary types. #121776 - Fixed an issue when sending the data to backend about password fields in database connectors' wizard. #122750
- Fixed a defect preventing data preview from being generated upon successful ingestion in certain circumstances. #121161
- Fixed an issue when using
ConsolidationMode Merge, where the merge query failed if field starts by a number. #123218 - Fixed a deployment issue where
DeployPowerBIReportsjob was not executed, due to a sanitization task performed incoredeploy. #120858 - Fixed an issue in intake pipelines caused by non change tracking configuration for incremental loads. #123260
- Fixed an issue where, if table is truncated in the source and Change Tracking expires, the table was truncated in the data lake before inserting/merging the new data. #123454
- Solved a problem with the Databricks setup script when setting or getting the KeyVault PlainSecret values. #123254
- Solved an issue where the automation account for auto-healing API availability issues was failing to execute and to restart the service automatically. #125656
- Fixed an issue where registering Data Products by extending the
ShortProductNamelength to 10 characters. #125593 - Fixed an issue due to a change in Databricks API that was preventing
Set-DatabricksSecretto work. #124867 - Solved a permissions issue when updating an existing Data Product by modifying and making the validations less restrictive. #124784
- Modified the limits in the tables per batch field in the database connectors wizard to fit better the infrastructure performance limits. #123977
- Fixed an issue in configure provider step of connectors wizard to validate for not accepting special characters. #122334
- Fixed an issue avoiding duplicated attribute name for the metadata. #124654
- Increased length for
SourceTypefield in Attribute table to solve a metadata creation issue. #124780 - Fixed a defect in Authorizations- Users in Sidra web by encoding URL arguments. #123699
- Fixed an interaction defect in Authorizations - Users where, editing the name of a user was taking to a non-existing page. #120777
- Solved a minor issue when failing to return an error when creating a delegation without receiving user. #123455
- Fixed an defect in Authorizations- API keys where a clear error was not returned while trying to save an API key with invalid fields. #123060
- Solved a minor issue when rendering error messages while attempting to create a delegation with incorrect start-end dates. #123453
- Fixed an issue with Azure-controlled purge protection policy when deploying KeyVaults. #125390
- Solved an problem when calling
RegisterAssetpipeline when a secret was missing. #125651 - Solved an issue about uninformative validation error in number of tables per batch input field in SQL and DB2 connector forms. #127063
- Solved a defect that was returning 500 error in a
POSTinLoadRestrictionObjectwhen it was actually a 400 error. #126060 - Solved a defect that was returning 500 error in a
DELETELoadRestrictionObjectwhen it was actually a 404 error. #126139 - Solved a typing issue with word
environmentin CLI script. #125645 - Fixed an issue where the list of Entities in Data Catalog for a Provider was being limited to 20 Entities. #125957
- Added the
ItemIdof a Provider in the response when calling to the API for a specific Provider. #124596 - Fixed an issue of missing validation in the object restriction list format in the database-type connectors wizard. #126189
- Fixed to prevent error in which an installation for a new environment did not automatically create DevOps environment for CD pipeline. #125233
- Solved an issue where
--createPowerBiAppparameter in the CLI installation was not properly setting the DevOps variable to true. #125849 - Fixed an issue in rolling back connectors plugin infrastructure when using an existing trigger. #125778
- Fixed an issue with Balea Reader role being assigned the incorrect permissions. #121875
- Fixed an issue for allowing unicode characters when an installation is registered in Llagar. #104840
- Solved a problem in Sidra CLI during the
install aadapplicationsstep, that was in endless loop during PAL association. #127064 - Fix an issue with the CLI tool, where
install aadapplicationsis asking for login when the user is already logged. #127057 - Fixed an issue in Sidra CLI tool, where
deploy sourcecommand logging traces of error incorrectly. #127063
Breaking Changes in Sidra 2021.R1¶
Use of LoadRestriction in ExtractMetadata activity¶
Description¶
A change in the
ExtractMetadataactivity has been made in order to use the newly implementedLoadRestrictiontables. This means that just in Sidra 1.9.0 version metadata extraction pipelines will not work.Required Action¶
If you are in Sidra version 1.9.0, please update Sidra version to 1.9.1 at least, preferably to 1.10 (this release).
SQL Server Admin password sanitization feature¶
Description¶
Sidra changes in SQL server Admin password sanitization feature comes with an undesired side-effect on PowerBI reports. Datasource credentials in Power BI reports may get outdated, whenever the deployment of Sidra Core updates the SQL admin password and the password does not meet the sanitization expression, and the
DeployPowerBIReportsstep is not triggered.Required Action¶
For existing Sidra installations (issue does not apply to new ones) we can mitigate this issue by ensuring that
PowerBiReportsEnabledvariable is set to true so as we can guarantee that theDatasourcecredentials are always up to date.
Dummy Asset generation not enabled by default¶
Description¶
Sidra databases loading pipelines create a dummy Asset (with size null) when they detect a table has no changes since last execution. This allows the
Syncwebjob to know that the loading of that table was already done, even if there are not new data in that incremental load.Por performance reasons, this dummy Assets are now optional and are NOT be generated by default. Since version 1.10, the pipeline has a new parameter to force the generation in case you want to, but the default value of that parameter is
false.Required Action¶
For existing deployed pipelines in existing installation that were using this dummy Asset configuration as
true, a Sidra deployment now deploys these pipelines asfalsenow. Please ensure that after a deployment of Sidra the pipelines are actually manually deployed with this parameter manually changed totrue.
Coming soon...¶
This 2021.R2 has been a very important release for Sidra, as it has added new connector plugins using the previously released plugin model. But not only that: this release represents an important step towards making the existing pipelines and data ingestion robust enough to handle many new scenarios.
The architectural foundations for Data Products plugin model, therefore, the ability to deploy Data Products from the web, has also been achieved as part of this Sidra version. This lays down the path towards a streamlined way of packaging Data Products so that its deployment is very simple to execute.
As part of the next release, we are planning to deliver our first Sidra-owned Data Product plugin, with a basic SQL Data Product as the first plugin of its type. Also, we plan to proceed further with the plugin model to allow further scenarios of plugin update configuration or plugin upgrades.
New plugins will be added to the gallery of connectors following a release cycle that no longer needs to be tied to Sidra Core release cycle.
Feedback¶
We would love to hear from you! You can make a product suggestion, report an issue, ask questions, find answers, and propose new features by reaching out to us in [email protected].