Sidra Data Platform (version 2021.R1: Inquisitive Idared)¶
released on Apr 27, 2021
This first Release of 2021 comes with a massive upgrade to the self-service capabilities Sidra, thanks to the new support for certain common operations in Sidra's Web UI. This took a little bit longer to release than initially expected, but we are sure you will love all the new capabilities!
The key feature that is released as part of this version is the support of configuration of data intake connectors from the Web UI, as well as the release of the first two new connectors. This has been possible thanks to an important architectural overhaul, which manages to wrap the logic of each connector in independent modules, called plugins.
Connectors for Sidra represent a new way of configuring data sources, through an easy-to-use interface embedded in Sidra Web. It also provides a way for both Plain Concepts and its partners to decouple data source connections from the different Sidra releases, allowing for a continuous stream of new connectors to be released without requiring users to perform a Sidra re-deployment.
It is important to note that the architectural work done to enable this feature has also set the foundations of another important track of improvements in self-service configuration and operations in Sidra: creation and management of Data Products from the Web, with this exciting new feature being planned for the next release.
On top of that, this Release comes with important features around the operability of the platform, both from the web, and from the perspective of other operational tools.
Sidra 2021.R1 Release Overview¶
This release comes with very significant features and improvements, some of which represent a big architectural change that is the cornerstone of the new Sidra:
- Data connectors UI support
- Azure SQL connector
- SQL Server connector
- Provider import/export
- Data Catalog Attributes view
- Improved telemetry
- Web UI improvements
What's new in Sidra 2021.R1¶
Data connectors UI support¶
Data connectors UI support is a major feature whose key exponent is visible in the Sidra Web UI. Sidra connectors have been conceived with the purpose of adding more self-service capabilities to Sidra. This has been, and will continue to be, one of the key objectives of Sidra evolution as a product.
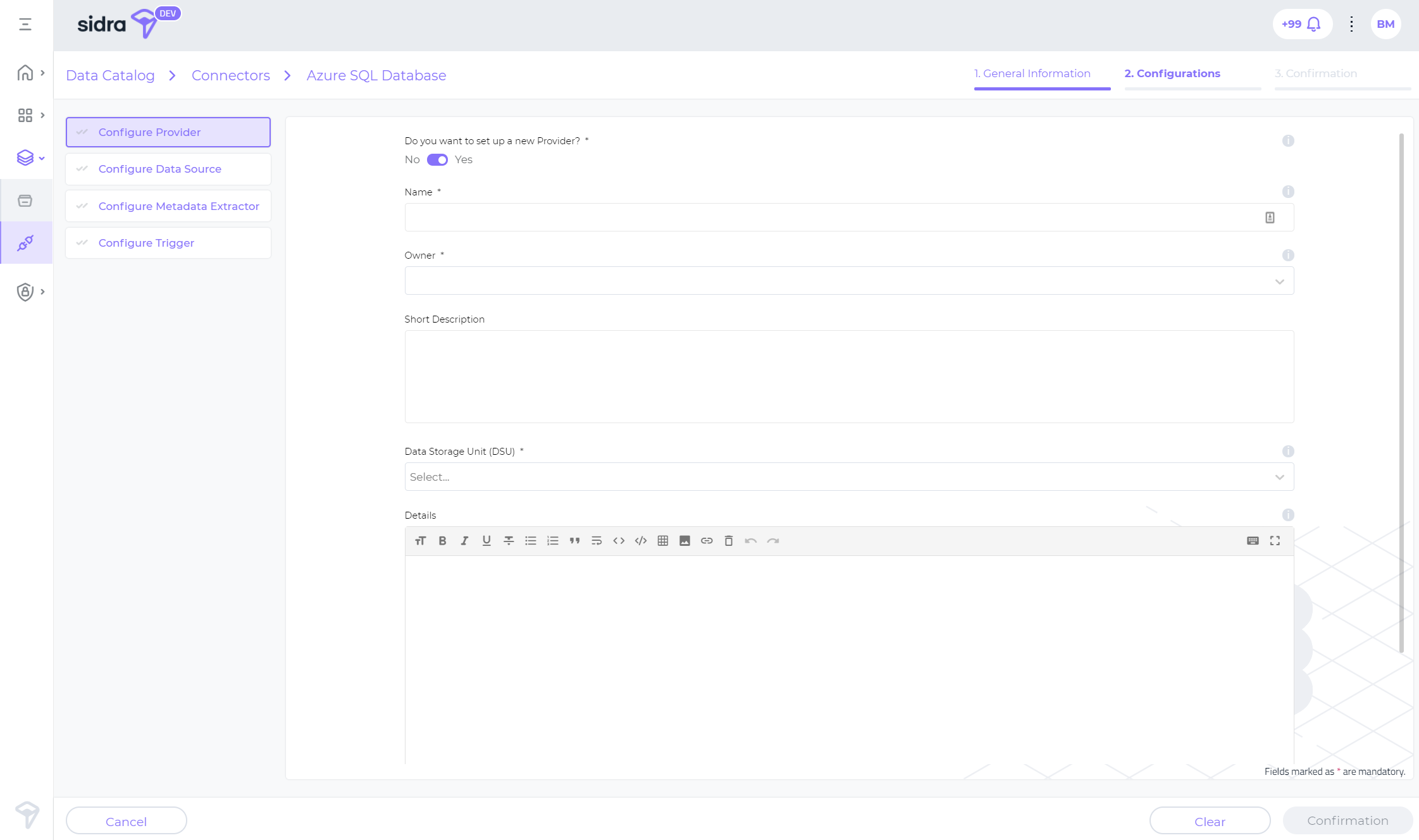
Connectors greatly simplify the configuration of new data source intake in a Sidra Data Storage Unit. Before data connectors, the configuration of a new data source required several calls to the API (e.g., for configuring metadata, triggers, etc), or alternatively setting up the metadata directly on Sidra's Core database with SQL scripts. While these methods will still be available for advanced set-up scenarios, with the new connectors the process is now greatly simplified, as the connectors' approach just requires the user to fill in a series of fields in a step-by-step wizard (Data > Connectors).
When configuring and executing a Sidra connector from Sidra web, several underlying steps are involved. On one hand, the necessary metadata and data governance structures are created in Sidra. On the other hand, the actual data integration infrastructure (e.g., pipelines) is created, configured and deployed.
A typical connector is configured in less than five-minutes. Just after the user provides a few details and confirms, all the orchestration will happen and the data intake pipelines for the new data source will be up and running.
Starting from this release, Sidra's roadmap will incrementally add support for different data sources through the connectors interface.
Release 2021.R1 comes with out of the box support for two connectors: Azure SQL Database and SQL Server. These are described below.
Sidra web users with Admin privileges can see the gallery with available connectors under the Data menu in Sidra Web:

Next, the user is taken through a set of steps (wizard mode), to add the needed configuration for that connector.
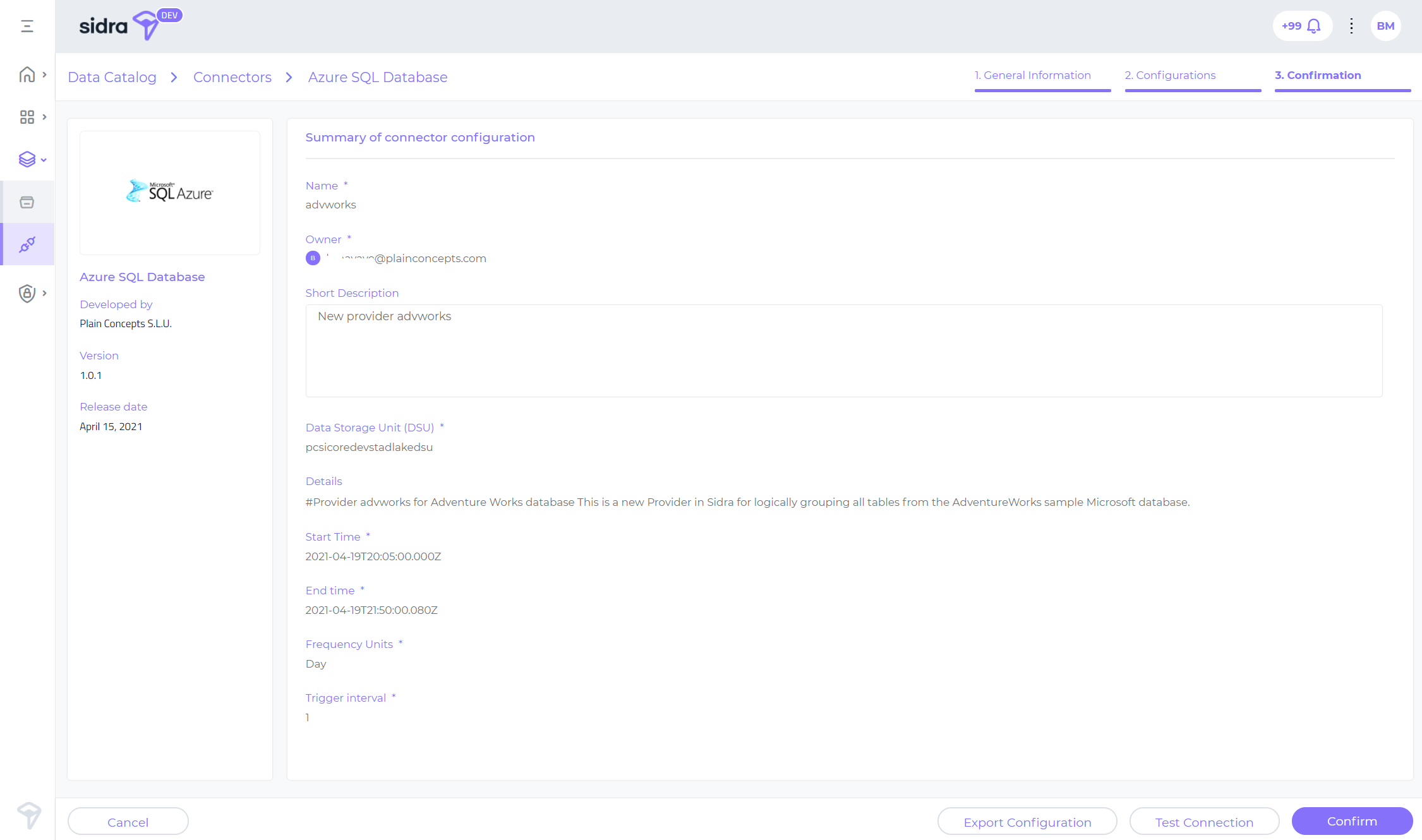
Before confirming the creation of the underlying infrastructure, there is the possibility to validate the connection or to export the configuration as a JSON file.
Azure SQL connector¶
The Azure SQL database connector for Sidra enables seamless integration with the most widely used SQL Server database as a Service on Azure; an intelligent, scalable, relational database service built in for the cloud. Azure SQL Database uses the latest SQL Server capabilities, and you can learn more about it on Microsoft Documentation.
Sidra's connector for Azure SQL database extracts data from any table and view in the source database and loads it into the specified Data Storage Unit at regular intervals. It relies on the Sidra Metadata Model for mapping source data structures to Sidra as destination, and uses Azure Data Factory as underlying data integration mechanism within Sidra.
When configuring and executing this connector, several underlying steps are involved to achieve the following:
- The necessary metadata and data governance structures are created and populated in Sidra.
- The actual data integration infrastructure (ADF Pipeline) is created, configured and deployed.
After starting the connector creation process, users will receive a message that the process has started and will continue in the background. Users will be able to navigate through Sidra Web as usual while this process happens.
Once the whole deployment process is finished, users will receive a notification in Sidra Web Notifications widget. If this process went successfully, the new data structures (new Entities) will appear in the Data Catalog automatically, and the data intake process will incorporate this new data source.
The Azure SQL Database connector for Sidra supports different modes of data synchronization, which also depend on the mechanisms configured on the source system or Sidra metadata:
-
Full load data synchronization: Generally performed for first time loads. This is also the default mode if no Change Tracking is enabled in the source system, nor alternative incremental load mechanism is defined. By default, the first load will be a complete load.
-
Incremental load data synchronization: This data synchronization mechanism captures updates for any new or modified data from the source database. Only data corresponding to the updates since the last synchronization is retrieved.
For incremental load to work, there must be a defined mechanism to capture updates in the source system. For incremental load data synchronization, two possible types of mechanisms are supported:
-
Incremental Load with built-in SQL Server Change Tracking (CT): This is achieved by directly activating Change Tracking in the source database.
-
Incremental Load non-Change Tracking related (non-CT): This is achieved by specific configurations in the Sidra Metadata tables.
You can see more details about how this connector works and a setup guide in the documentation.
SQL Server connector¶
The SQL Server connector for Sidra enables seamless integration with Microsoft's powerful enterprise relational database .
Sidra's connector for SQL Server extracts data from any table and view in the source database and loads it into the specified Data Storage Unit at regular intervals. It relies on the Sidra metadata model for mapping source data structures to Sidra as destination, and uses Azure Data Factory as underlying data integration mechanism within Sidra.
Similarly to the Azure SQL connector, when configuring and executing this connector, the metadata and data integration infrastructures are created and deployed. The user will receive a notification once the whole deployment process is finished.
The following list includes all SQL Server versions supported by this connector:
- SQL Server 2008 R2 (version 10.5.xx)
- SQL Server 2012 (version 11.xx)
- SQL Server 2014 (version 12.xx)
- SQL Server 2016 (version 13.xx)
- SQL Server 2017 (version 14.xx)
- SQL Server 2019 (version 15.xx)
Note: All editions (Developer, Standard and Enterprise) are supported, but some features of the connector will only be available if the source SQL Server edition supports the feature, such as the Enterprise edition requirement for Change Tracking on tables.
The SQL Server connector supports the same modes of data synchronization than the Azure SQL Database.
You can see more details about how this connector works and a setup guide in the documentation .
Provider Import/Export¶
As a continued effort to ease the use of the installation and configuration of Sidra, the Sidra CLI tool now includes the capability to automatically export data about a Provider (including its Entities and Attributes) from one environment (ex. dev), and to import this data into another environment in the same or different installation.
The procedure just needs to be run once per destination environment to replicate the configured metadata. From the implementation perspective, the data is copied transparently to an intermediate staging database, and data migrations are applied up or down to set the same migration at the destination.
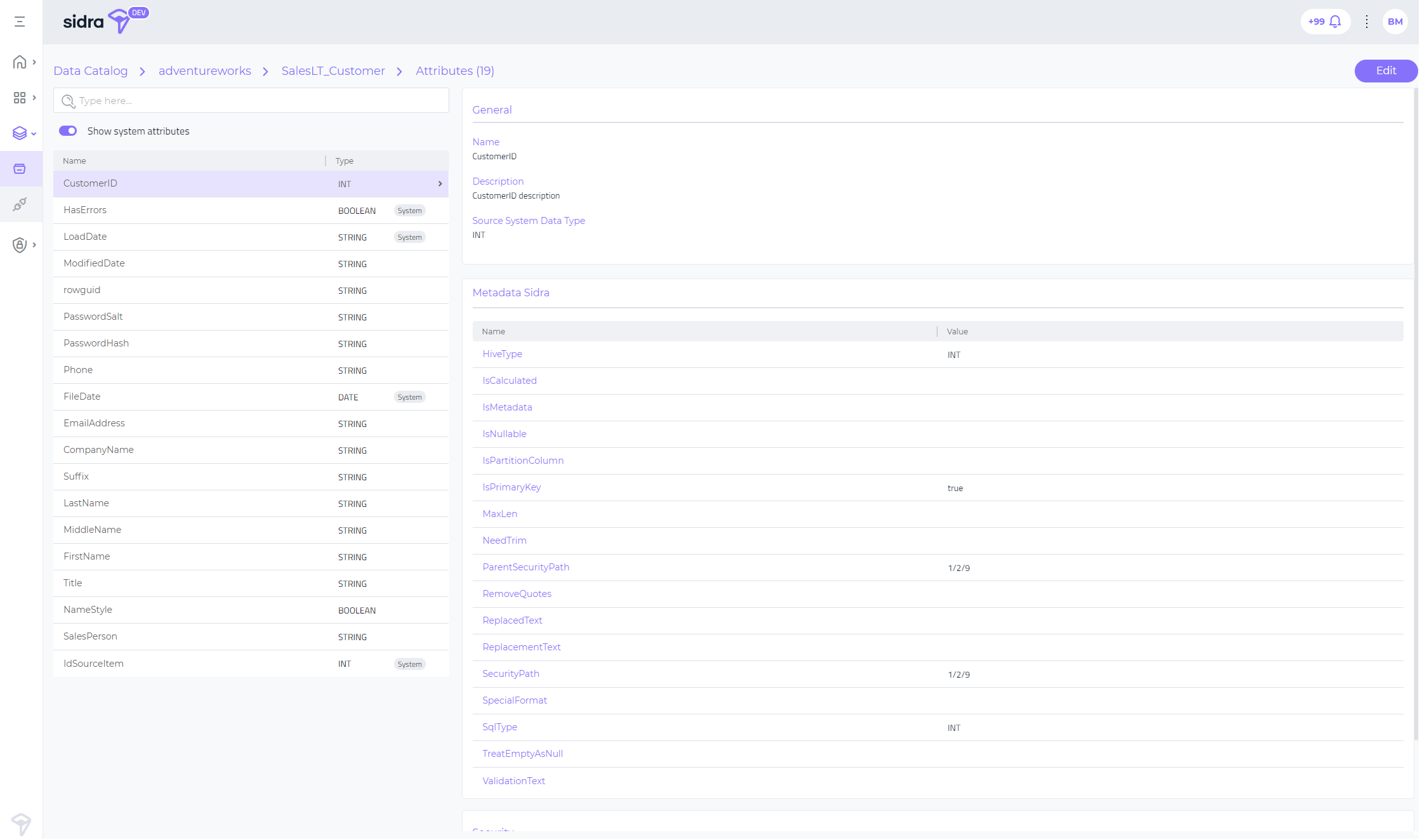
Data Catalog Attributes view¶
This feature completes the whole view of the Sidra metadata from Sidra Web, by including a new Attributes detail view for each Entity. After selecting the specific Entity, the user can choose to delve into the whole list of Attributes (See All Attributes option), that are defined in the metadata system for that Entity. This includes the Attributes originated from the source system, as well as the System Attributes - those technical Attributes created by Sidra for conveying information on how to process a specific Entity.
For each Attribute, the Attributes view allows to see all relevant fields organized in sub-sections: General, Metadata and Security.
Improved telemetry¶
This feature allows the support team at Sidra to have access to operational data from Sidra Core installations.
As of Release 2020.R3, each Sidra installation had access to a set of operational Power BI reports providing key insights on data intake figures: volume stored, pipeline executions, etc. With this release, now customers opting-in to send telemetry operational data will benefit from an enhanced monitoring and operability from the Sidra team. The insights gathered from this telemetry will allow to react early in time about possible anomalies and operational errors, as well as to better customize the product to the customer's needs.
The telemetry job will be transparent to the customer, and gather data about key intake metrics, errors, warnings, notifications and service daily metrics.
Web UI improvements¶
This release continues building on the functionalities and improvements of Sidra Web, across different sections:
-
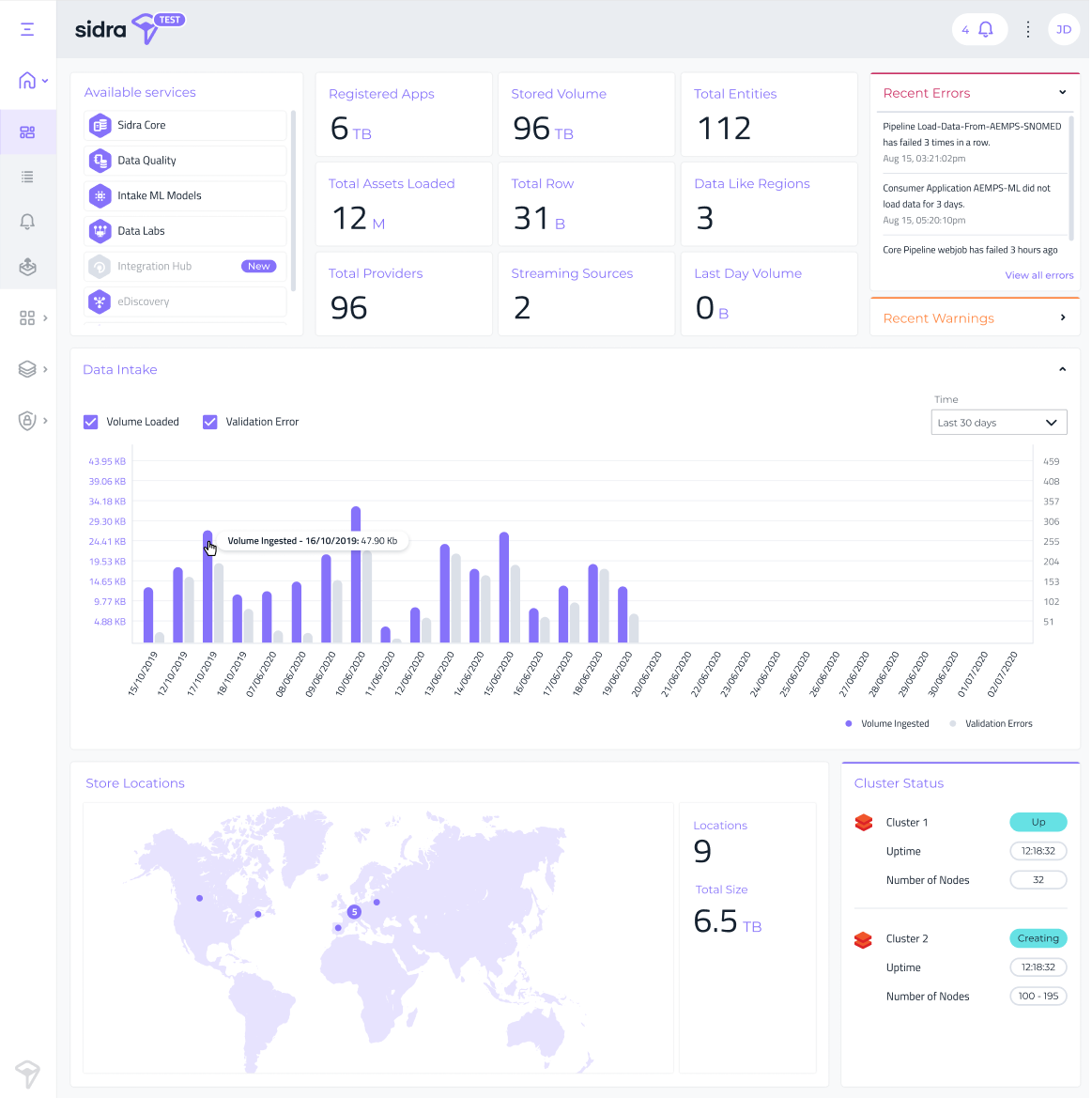
New Dashboard layout:
Sidra's Dashboard page has been redesigned, with improved utilization of real state for Data Intake graphs and Cluster status. An improved widget has been added for geo-visualization of the different Data Storage Units.
-
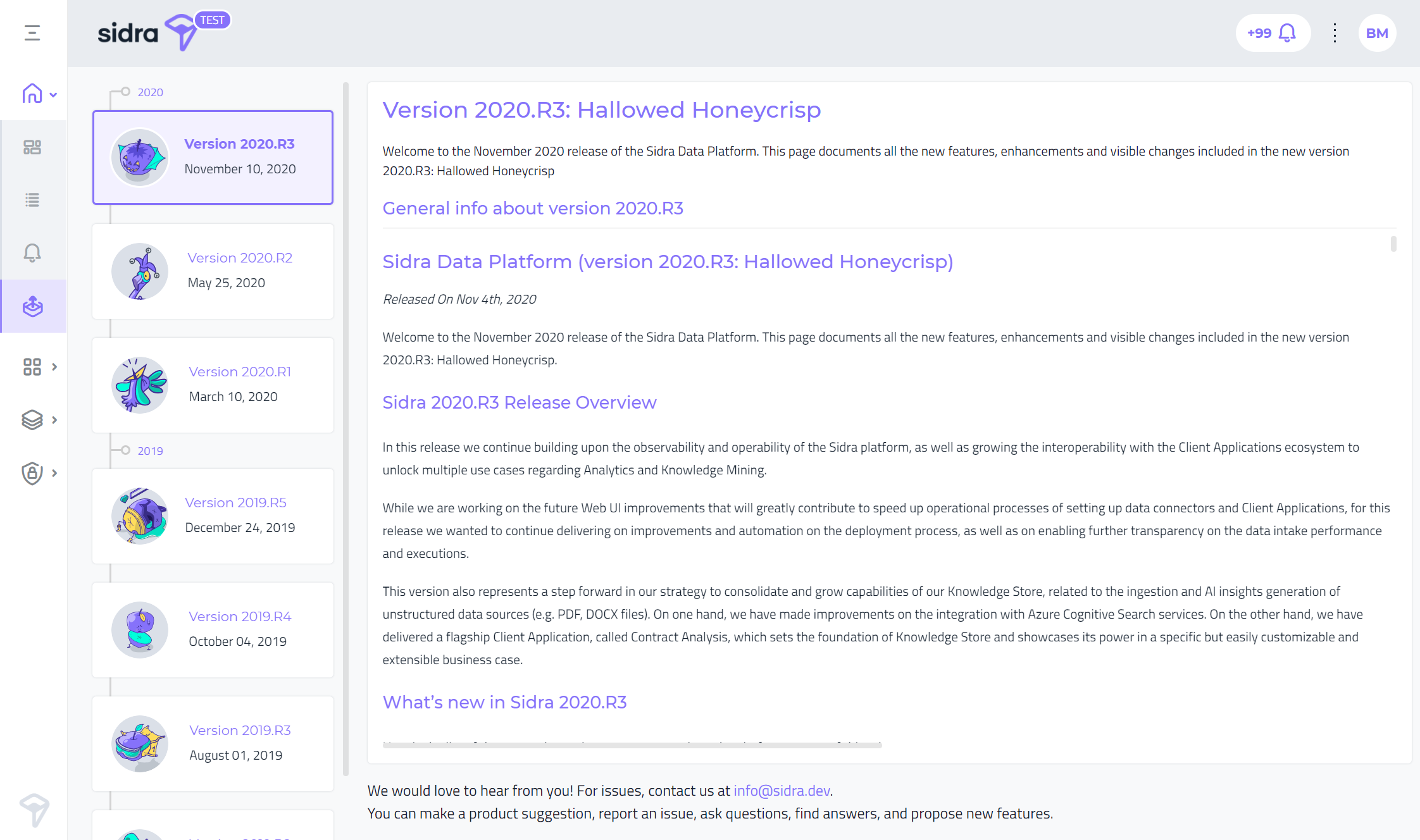
Release notes redesign:
The Release notes page in Sidra web has been re-designed, with the objective of displaying a linear timeline of all the Releases of Sidra.
-
Data Catalog improved visualization for Entity types:
The Data Catalog now includes an improved support for displaying the format of an Entity. Entity format (e.g., parquet, csv) is now displayed with an icon in the Entity detail page. Entity list also includes a column with the Entity format.
-
Layout review and issues corrections across different sections of Sidra Web:
A very large number of relatively minor cosmetic changes and improvements have also been made during these last months since last Release of 2020.
We have improved some layout issues across the Data Catalog and improved the performance of the Logs page. We have also improved the visualization of tags in Entities and Providers cards view.
Issues fixed in Sidra 2021.R1¶
This has been a significant effort accomplished in terms of product stabilization and bug fixing, with some of the more relevant bugs and improvements listed below:
- Solved an issue in
api/tabular/refresh endpoint, which now returns a 202 accepted to support polling strategy which is natively supported in ADF. #101730 - Fixed and error on authentication when Client Secret contains some special characters. #98222
- Fixed an issue where, under certain conditions, the Databricks linked service was not created correctly. #102347
- Solved a problem where, when the DSU is deployed for first time in any environment, the Linked Service created in ADF is not properly configured. #102824
- Corrected TabularRefresh to no longer return a 200 (OK) when the process fails. #103509
- Fixed issue when trying to parse KeyVault placeholders when pipeline definition JSON was not split into multiple lines. #103521
- Fixed an issue with DataLabs Data Product template, which was not building properly due to a bad version in Serilog.Sinks.ApplicationInsights and a wrong usage configuration of the LogAnalytics workspace. #103564
- Fixed an issue under certain conditions when a filter was specified to retrieve the Providers. #102741
- Fixed an issue that could generate invalid internal credentials to encrypt the data when using encryption pipelines. #103433
- Solved an issue that was preventing users or applications to retrieve tokens to upload files to the landing zone unless they are with admin role. #102310
- Solved an issue in the SqlAdminUser variable, when it was created in the Common group, causing issues when the Data Product was trying to publish its own variable with the same name. #103273
- Fixed an issue in TriggerTemplate, by adding support to the new field TimeZone. #103518
- Fixed an issue where (N)CHAR fields were created without specific size, and solved by handling similarly to (N)VARCHAR. #105769
- Solved an issue with tabular model endpoint by enabling the tables creation with "Value" column enabling IsHidden attribute, which helps to simplify the tabular model. #104637
- Corrected a situation when an internal step was missing to deploy all the packages required to perform a deployment. #104582
- Fixed an issue in the Update CLI command to support authentication based on PAT token for update operations. #104666
- Fixed an issue with DW deployment and procedures, where scoped credentials were not updated in each deployment. #104667
- Fixed a problem of compatibility in Data Products for 1.8. #104828
- Fixed an issue happening in migrations from > 1.7 versions to 1.8 in DW structure. #104888
- Fixed an issue where the connection string settings for App Services where not removed in the migration after 1.8 version, generating a failure in the process. #104910
- Solved an issue that caused an error in the execution of a job to update the operation dashboard. #104914
- Fixed an issue in the data extraction pipeline template for incremental loads in SQL related to conversion between varchar and timestamp. #105070
- Fixed an issue in the Data Product pipeline for extracting data from the DSU when the pipeline includes autoscaling for the database. #106019
- Fixed an issue with invalid package version in sidraintake cluster initialization. #105052
- Solved an issue happening in redeploys in App Services, which were reading in memory settings with stale values. Settings are now being refreshed after the first deployment after forcing a stop and start of the whole IS app service. #105196
- Fixed an issue in the template for the pipeline that extracts the metadata for an SQL source, by using ProviderItemId parameter and updating the query in the Lookup activities. #108207
- Corrected an issue in pySidra package, by forcing the upgrade of such package in Databricks cluster if already installed. #108183
- Fixed an issue where RunTransferQuery was failing when the raw file was copied to the final blob if the file was too big (more than 200Gb). Removed use of dbutils package in favour of using blob client. #108993
- Fixed an issue when non-supported SQL types were triggering an error in ADF CopyActivity when copying from SQL to Parquet. Solved the issue by arranging type translations in the TypeTranslation table for different types: SQL_VARIANT, GEOGRAPHY, VARBINARY, HIERARCHYID, GEOMETRY, BINARY. #107086
- Fixed a limitation in the Regular Expression field in the Entity metadata table, by increasing the length to 500 characters to support possible long table names. #106867
- Fixed an issue when the permissions for a Data Product were configured to remove the old permissions. #108719
- Solved an issue in Sidra web for notifications mark as read functionality. #103762
- Solved an issue in Sidra web where filter by tags was not working in the Data Catalog. #105910
- Fixed an issue in Sidra web where Log The 'Data Factory Log' list couldn't be filtered with the 'Description' field. #107152
- Fixed an incorrect namespace in Core solution template. #111635
- Fixed an issue where the ClientApp-adminUser and ClientApp-adminPassword were using core KeyVault name. 3110842
- Fixed a parametrization option in Data Products deployment script, so that the preferred Azure PowerShell and module version are passed as parameter to the Azure DevOps pipelines. #111071
- Fixed an issue with "Get-AzKeyVaultSecret" by changing AzureRM to Az. #111943
- Added a fix for an issue to gracefully detect the error related to the Hangfire jobs queued as background task when more than one instance of the queue is detected. #112043
- Fixed an error importing modules in a Databricks notebook AzureSearchKnowledgeStoreIngestion by changing to the correct package imports. 3112206
- Fixed an issue with GetEffectivePermissions that was referencing Datalake old term (new is DSU). #111940
- Solved an issue in deployment script by removing deprecated Powershell functions Get-AzureKeyVaultSecret and Get-AzureKeyVaultSecret and replacing them with the correct ones. #111782
- Fixed an error in AddAuthentication options in Startup.cs for PythonClient build, by explicitly adding the AuthenticationScheme and DefaultSignInScheme options. #111588
- Added a fix to show more valuable messages in deployment scripts. #111404
- Fixed an issue in the data extraction pipeline template for incremental loads in SQL when Change Tracking is not used. #109461
- Fixed an error produced where IsMerged field in Entity was being used to do a merge when tables are other than Delta. Simplified control of merging option to just use the ConsolidationMode = "Merged" in AdditionalProperties, which is the mechanism used with Delta. #105740
- Solved an issue where deployment template for Data Products was missing the assigned identity by default, which is required to manage the KeyVault access policies. #109748
- Fixed an issue when creating a container in a storage account, where destinationUri was formed by using the Provider name with no sanitization. #110266
- Added a fix to enable Enable-AzureRmAlias in clientdeploy.ps1 script and modify task version in release-stage. #110670
- Fixed a problem while attempting to install Open-Jdk() through the Integration Runttime gatweway install script. #108721
- Improved the messages logged when running deployment script ClientDeploy.ps1. #111294
- Fixed an issue in creating staging tables procedure when there were deleted rows with Change Tracking activated. Now, all columns, except metadata columns, in staging tables are forced NULL, in order to support deleted rows when Change Tracking is enabled. #110978
- Solved a permission issue by adjusting Balea reader role to allow the following actions: see users, API keys, permissions and assigned roles to apps. #113386
- Solved a permission issue by adjusting Balea AppContributor role to allow to see Data Products through the website, as well as create new Data Products if required. #111400
- Permission on DataCatalogAnnotator role added to be able to read the information from the data catalog. #111401
- Fixed an error in login using interactive flows with IdentityServer due to an update in IdentityServer to add support for internal users. #113748
- Added a fix to an issue in Databricks notebook with a wrong enconding. #112906
- Solved an incorrect namespace in Core solution template. #111635
- Fixed an issue where the ClientApp-adminUser and ClientApp-adminPassword were using core KeyVault name. #110842
- Fixed a parametrization option in ClientApps deployment script, so that the preferred Azure PowerShell and module version are passed as parameter to the Azure DevOps pipelines. #111071
- Solved an issue in the pipeline template for extract metadata from a TSQL source where some default values were not provided in the pipeline definition. #112417
- Fixed an issue to gracefully detect the error related to the Hangfire jobs queued as background task when more than one instance of the queue is detected. #112043
- Added a fix for an error importing modules in a Databricks notebook AzureSearchKnowledgeStoreIngestion by changing to the correct package imports. #112206
- Solved an issue in executing deployment scripts, by removing dependencies with deprecated AzureRm module from these deployment scripts. #112462
- Fixed an issue in deployment script by removing deprecated Powershell functions Get-AzureKeyVaultSecret and Get-AzureKeyVaultSecret and replacing them with the correct ones. #111782
- Solved an error in AddAuthentication options in Startup.cs for PythonClient build, by explicitly adding the AuthenticationScheme and DefaultSignInScheme options. #111588
- Fixed an error that was produced when capturing insufficient instrumentation in Application Insights - Traces module, by reverting references to v2.14. #110336
- Fixed an issue retrieving values from the KeyVault under certain circumstances. #112441
- Sovled an issue creating the a file in the storage account with the new version of the encryption process. #112837
- Fixed an issue with the module 'SignalRCore' in Databricks notebooks causing the Anomaly Detection activity to fail after a refactor in module SignalRCore. #112475
- Added a fix for a problem in SidraCLI tool, where the Sidra version and number was not updated in DevOps when updating the Sidra version. #112440
- Fixed an issue where variable DEPLOYMENTOWNERNAME could not be retrieved despite having a value in DevOps. #112439
- Fixed an issue decrypting parquet files when padding characters were added in the encryption process. #113205
- Solved an issue where indexers creation was failing depending under some conditions. #112254
- Fixed an issue that prevented creating or updating background jobs. #113423
- Added a fix for an issue in the template for the pipeline that extracts the metadata for a DB2 source. #112616
- Solved an issue when converting DB2 queries to Entity metadata with data type Character, by using the Char type instead. #113210
- Solved a type conversion issue that affected DB2's character varying data type, by transforming to varchar.#113254
- Fixed an issue when selecting a database in DB2 or MySQL with spaces in its name. #113247
- Solved a type conversion issue that affected DB2's time and timestamp type, by using the Datetime2 type. #113276
- Enhanced the details of the response body of some endpoints. Now ProviderItemId is included. #113461
- Solved an issue triggered by token expiring while executing GetPipelienExecutionLogsFromDataFactory, by adding retry policies to datafactory helper GetActivityRuns.#112478
- Fixed a problem in Core and Apps dotnet templates, where invalid chars were making the yaml invalid. Fixed by sanitizing templates with regexp. #112293
- Fixed an issue if KeyVault connectivity issues during startup phase that was preventing startup of the sites. Solved by adding retry policy in KeyVault configuration. #104908
- Fixed a problem with encryption when the colum contained special characters, by using a Fernet encryption method. #113387
- Adjusted a permission on DataCatalogContributor role, by adding permission to read information from Data Catalog. #112434
- Fixed an issue on the step to retrieve the internal version of Sidra installed, which is used when the first installation is performed. #113804
- Fixed an issue in DeployAllUpdatedAsync to force deletion of those pipelines that are marked IsRemoved correctly. #114733
- Solved an issue where the endpoint
api/datafactory/Pipelines/deployAllUpdatedwas not using the parameter ValidUntil, by adding support for that parameter. #114702 - Fixed an issue with an escaped character in DB2 pipeline. #114949
- Solved an problem where the endpoint GetAllAsync filter was not working as expected. #115113
- Solved an issue in getting ItemId for a Provider, so that when a Provider is created, it returns the ItemId. #115222
- Added a fix for an issue in the template for the pipeline that extract the metadata for a MySQL data source. #113413
- Fixed an issue in the unstructured data process, which didn't work when using the index landing folder. #110186
Breaking Changes in Sidra 2021.R1¶
Encryption process changes¶
Description¶
This Release includes a major update in the process of ingesting and processing files with encryption. The encryption process has been updated to ensure that the unencrypted raw copy is not stored in the same location as the encrypted raw copy. Before this modification, the
RegisterAssetpipeline moved the file to the raw zone and after that, theFileIngestionWithEncryptionpipeline encrypted the file in the same location. After this breaking change, theRegisterAssetpipeline moves the file to a temporary zone and, only once the file is encrypted, the file is moved to the raw zone. The transfer query script has been modified to decrypt the file in a temporary zone before ingesting the data in the DSU. Because of these modifications the pre-existingFileIngestionWithEncryptionpipeline is removed in favour of using theFileIngestionDatabrickspipeline.Required Action¶
The actions to be done need to be managed within Sidra update process. These actions include:
Recreating the Transfer Queries associated to the Entities with encryption.
Reassigning the pipelines for the Entities with encryption from
FileIngestionWithEncryptiontoFileIngestionDatabricks.The flag
IsEncryptedis automatically removed for the Assets because it is not used anymore from version 1.8.2.
Removed IsMerged field from Entity table¶
Description¶
IsMerged field in Entity is no longer used and it has been decommissioned.
From Release 1.8.2, the merge consolidation mode is defined not by the Attribute IsMerged from the Entity, but from the AdditionalProperties, by setting "ConsolidationMode = Merge".
Required Action¶
Use Delta tables and AdditionalProperties instead of IsMerged Attribute. Use "Consolidation Mode = Merge" in the AdditionalProperties field to specify merge mode.
Support for multiple Integration Runtimes¶
Description¶
Support for multiple Integration Runtimes feature brings a breaking change on existing 1.8 Sidra Core Installations ("parameter cannot be found that matches parameter 'includeIntegrationRuntime'").
Required Action¶
If already on Sidra 1.8, you need to update using Sidra CLI to get the latest updates on the DSU deployment templates. These are the steps required:
- Create Profile:
.\sidra.exe profile create --devOpsProjectUrl "https://dev.azure.com/[urproject]" --devOpsPAT "[urPAT]" --devOpsProject "[Devops project]" --environment "[env]"
- Create library and KeyVault:
sidra deploy configure --deploymentOwnerName "[ownername]"--deploymentOwnerEmail "[owner]@plainconcepts.com"--infrastructureAlertEmail "[owner]@plainconcepts.com"--companyName "[companyname]"--sidraAdminSubject "[admin]@plainconcepts.com"--subscriptionId "[subscription]"--coreKeyVaultName "[keyvaultname]" --developmentTeam "Plain Concepts"--resourceGroupName "[resourceGroup]"--defaultDSUResourceGroupName "[replacewithyourresourcename]"--resourceNamePrefix "[replace]"--resourceNameMiddle "core"--installationSize "S"--llagarACRHost "sdsllagardevacr.azurecr.io"--llagarACRUser sdsllagardevacr
- Update:
.\sidra.exe deploy update
Requirement to use ItemID in pipeline API methods¶
Description¶
Providers and pipeline creation now create an ItemId (Global Unique identifier). This ItemId is required for creating and running pipelines.
Required Action¶
When creating or running a pipeline, please ensure to use the updated endpoints that include the itemId. Method
/api/datafactory/pipelines/{itemId}/executenow uses itemId instead of Id. Method/api/datafactory/pipelinesalso uses an itemId inside theparametersfield.API endpoints to retrieve pipelines and Providers have been updated to return the ItemId.
Coming soon...¶
This 2021.R1 has been a very important release for Sidra, since it has laid the architectural foundations for the intake Connectors and the Data Products wizard. In this release, the visible outcome has been the new Connectors UI in the web, whereas the next release will focus on the UI for deployment and configuration of Data Products from Sidra web.
As part of the next release we are planning to deliver the first Data Product template plugins, with a basic SQL Data Product as the first Data Product plugin, as well as the SDK that will enable end users to create their own, private Data Products as plugins.
Feedback¶
We would love to hear from you! You can make a product suggestion, report an issue, ask questions, find answers, and propose new features at [email protected].