Sidra Data Platform (version 2020.R3: Hallowed Honeycrisp)¶
released on Nov 4th, 2020
Welcome to the November 2020 release of the Sidra Data Platform. This page documents all the new features, enhancements and visible changes included in the new version 2020.R3: Hallowed Honeycrisp
Sidra 2020.R3 Release Overview¶
In this release we continue building upon the observability and operability of the Sidra platform, as well as growing the interoperability with the Data Products ecosystem to unlock multiple use cases regarding Analytics and Knowledge Mining.
While we are working on the future Web UI improvements that will greatly contribute to speed up operational processes of setting up data connectors and Data Products, for this release we wanted to continue delivering on improvements and automation on the deployment process, as well as on enabling further transparency on the data intake performance and executions.
This version also represents a step forward in our strategy to consolidate and grow capabilities of our Knowledge Store, related to the ingestion and AI insights generation of unstructured data sources (e.g. PDF, DOCX files). On one hand, we have made improvements on the integration with Azure AI Search services. On the other hand, we have delivered a flagship Data Product, called Contract Analysis, which sets the foundation of Knowledge Store and showcases its power in a specific but easily customizable and extensible business case.
What's new in Sidra 2020.R3¶
Here is the list of the most relevant improvements made to the platform as part of this release:
- New Sidra deployment tool
- Operational DW and Reports improvements
- New Web UI section for Authorization Management
- Improvements to the Azure AI Search pipelines
- Metadata inference API for CSV files
- New Application Insights Custom Events
- Improvements in Change Tracking for incremental load
- Updated Batch Account API version
- Updated Databricks to latest 7.2 runtime version
- Unified SignalR hubs for generic handling of notifications
- Automatic creation of staging tables for SQL client pipeline
New Sidra deployment tool¶
We have added a new installation command line interface (CLI) tool, which simplifies and improves several aspects of the previous installation and deployment process of Sidra across environments. The tool allows to package and automate deployment and installation tasks:
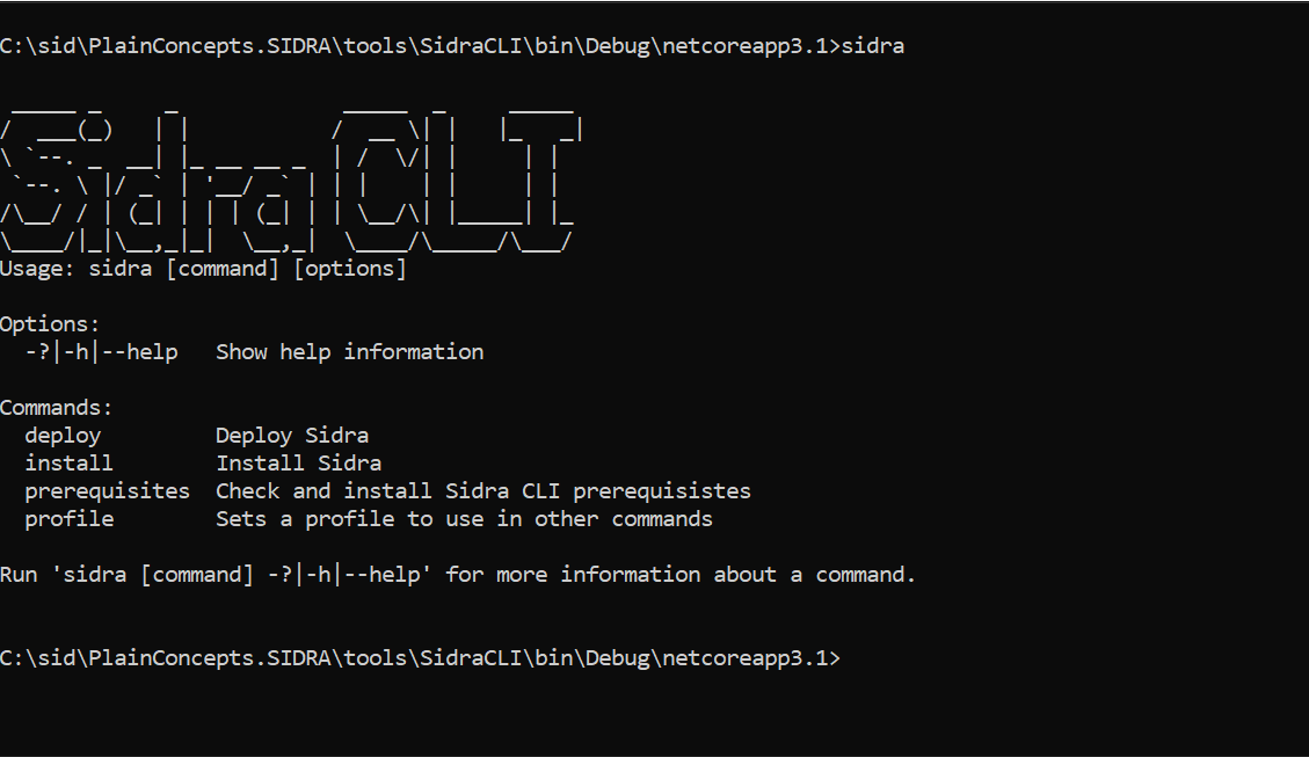
This CLI tool has been designed to cover for generic services of Sidra across client installations, including separate and differentiated stages for optional services. The available services are retrieved by the back-office service of Sidra to guide the installation process.
As new environments are configured, new stages are created for that environment in the deployment pipeline. The tool transparently manages the creation of different settings, including managing sensitive configurations through Key Vault.
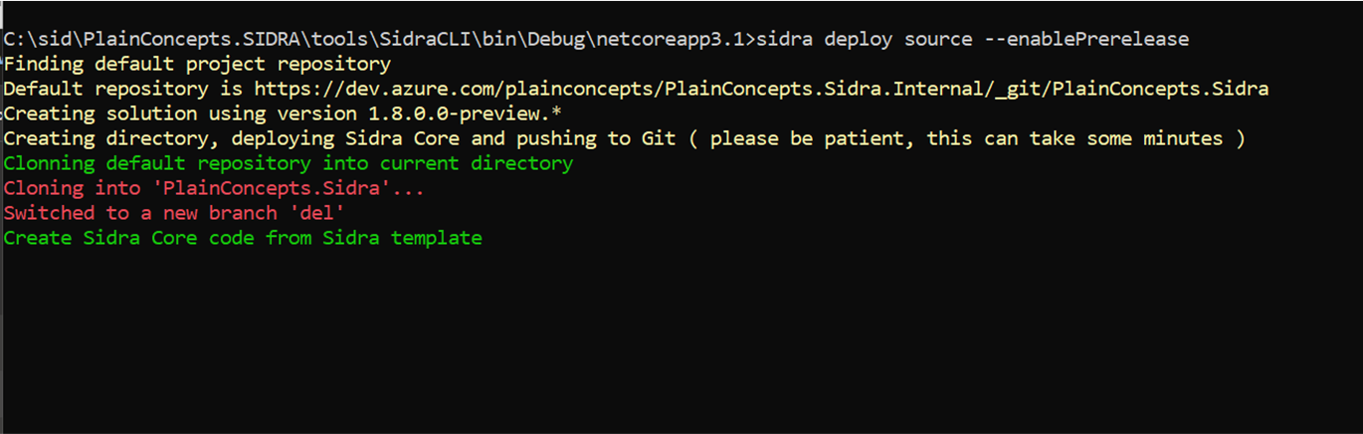
The CLI includes an option to deploy a pre-release version (preview), which will create the needed directories, deploy Sidra core and push to Git:
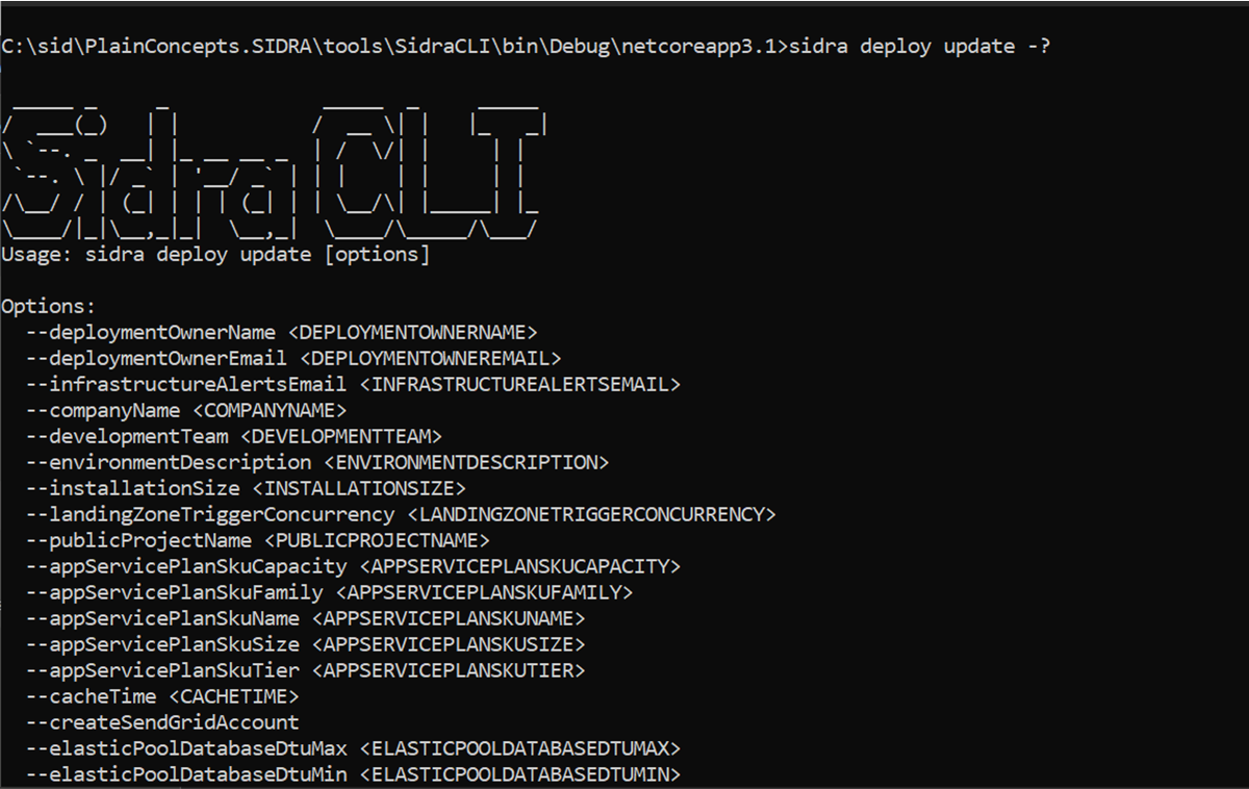
Update deployments have also been incorporated as an option in the Sidra CLI tool:
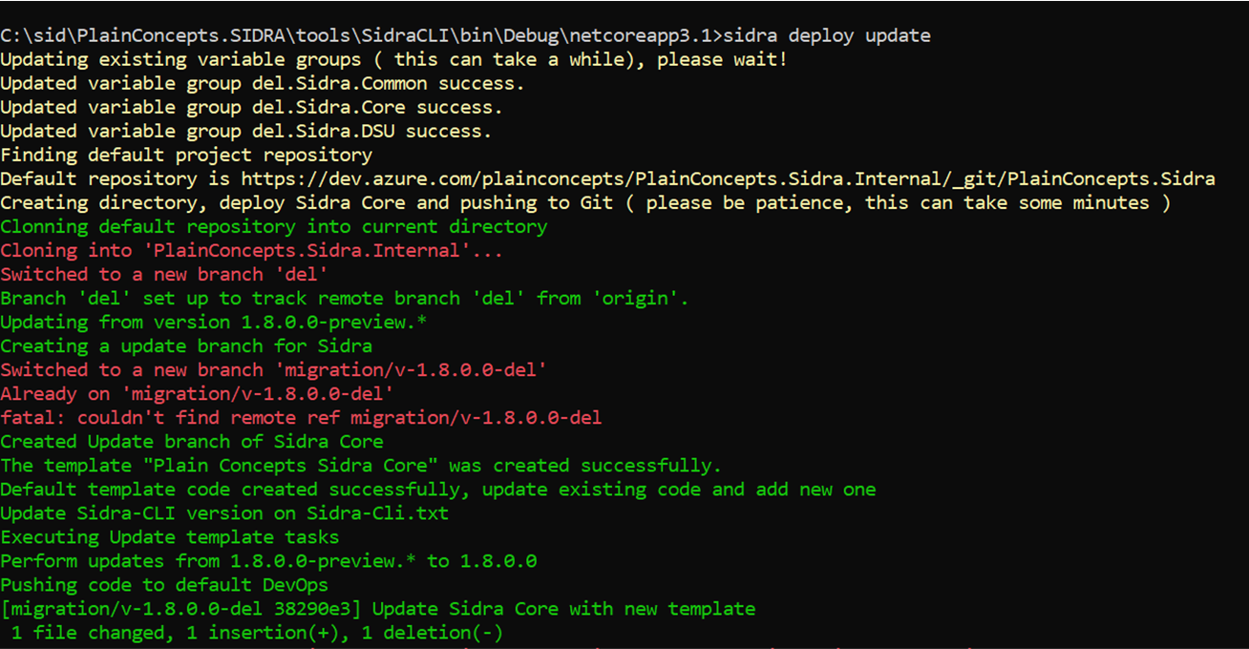
Once all params are configured for the update, or taking the existing ones by default, the update process is executed automatically:
Operational DW and Reports improvements¶
An important improvement coming in this release is the addition of further data and catalogue insights via Power BI reports on the Sidra DW. Several built-in Power BI reports have been made available to display performance indicators on the data intake pipelines, including trends and insights related to entities, volume of data stored, validation errors and pipeline executions status and execution lengths.
These Power BI reports are called to complement some of the operative information already available through the Sidra Web UI Dashboard and Data Catalog sections.
The Power BI DW reports aim at achieving a dynamic, interactive, and detailed view of intake process related information, according to the configurable selected time ranges. This way, we provide a consolidated point of view of the different operative data sources in Sidra, like Core and Log databases.
The DW Power BI reports for Sidra contain the following pre-configured dashboards:
-
Data Intake Report:
The Data Intake Report displays, for the selected time period in the slicer, different graphs and indicator cards regarding Data Intake volumes: total volume of data stored, percentage of validation, evolution of stored volumes and validation errors over time. This report also provides info on the total assets and number of rows ingested.
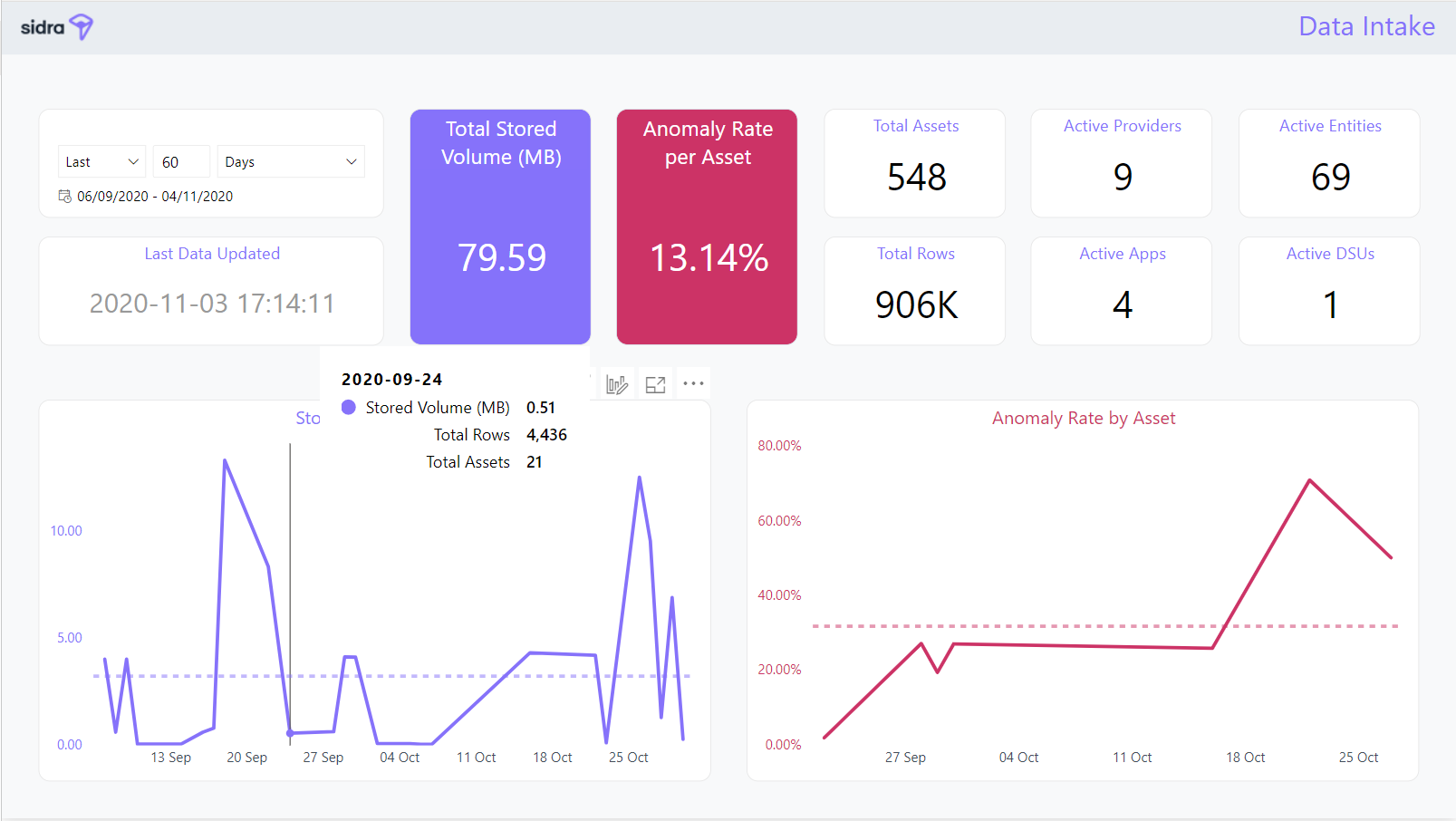
-
Pipeline Executions Report:
This report shows all information related to the overall pipeline executions and performance during the selected time period. In addition to key figures, some trend graphs display the evolution of executions of the pipelines and their duration vs the average pipeline execution duration.
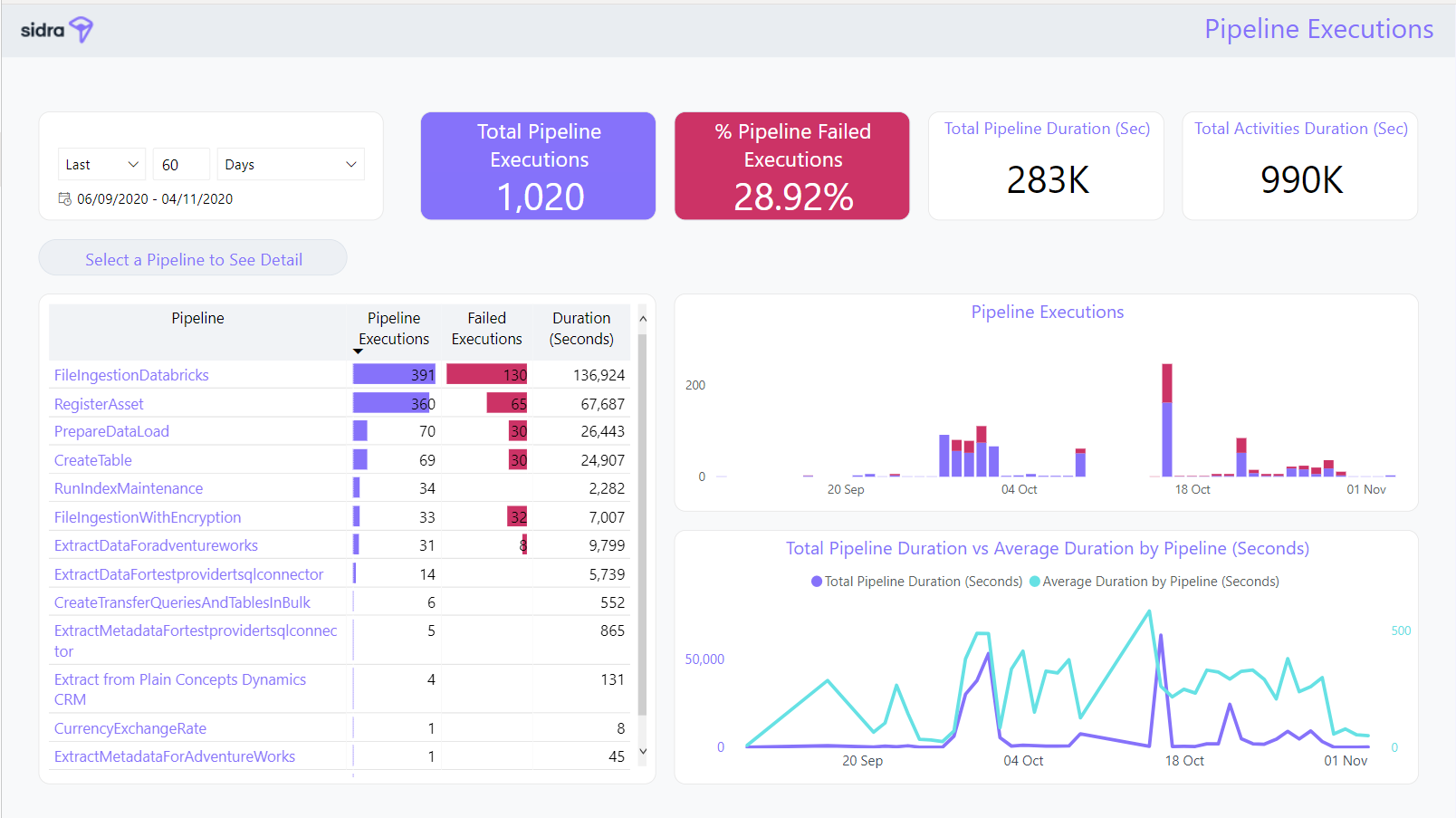
From here, users can drill through a specific pipeline to see more detailed information about the different Pipeline executions.
-
Detailed Pipeline Executions Report:
The Detailed Pipeline Executions Report gives information about the number of executions of the selected Pipeline by date and duration, as well as related activities. The dashboard contains a Pipeline RunList with details on each execution of the pipeline:
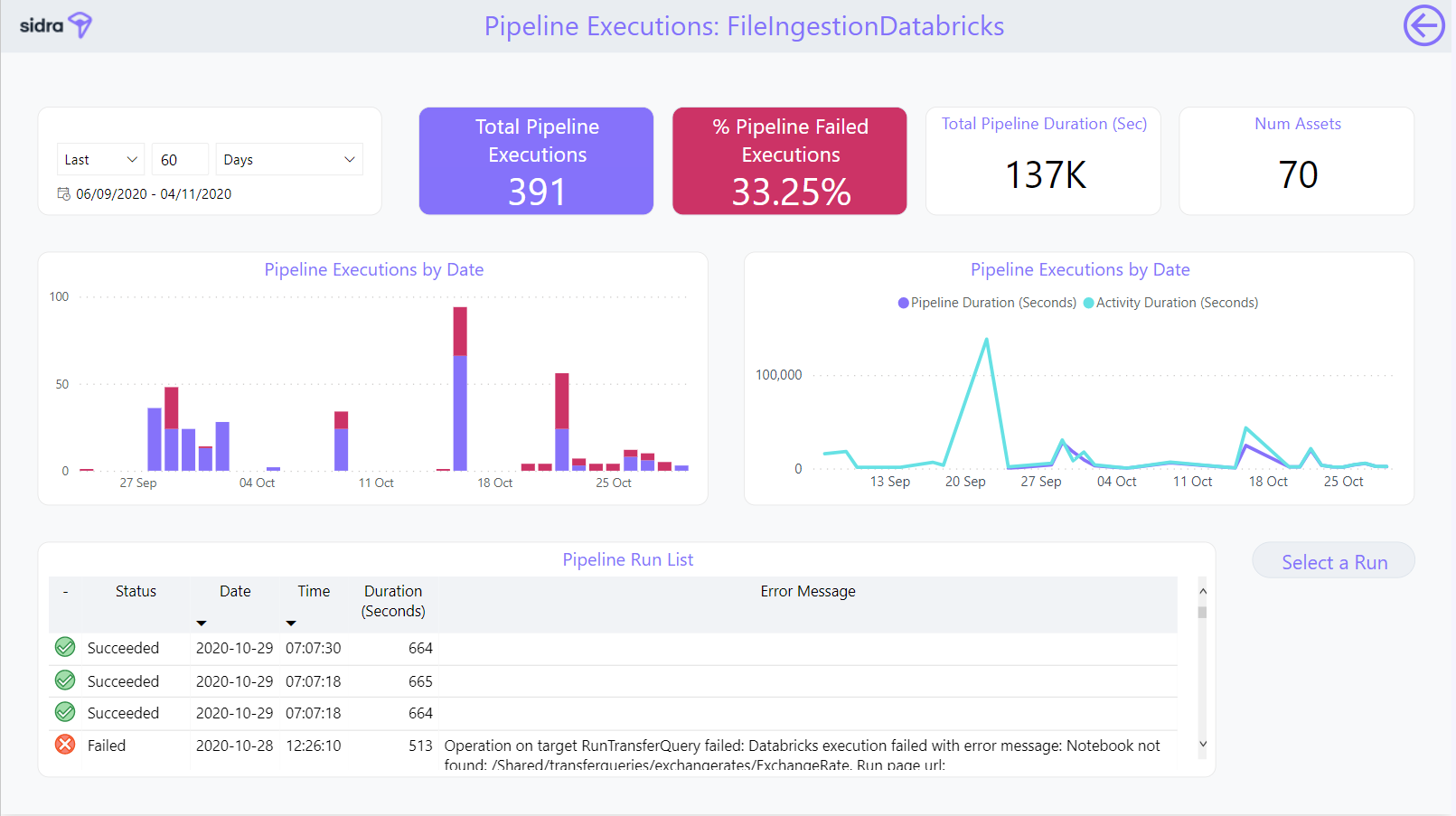
By selecting one of the pipeline executions from the list, users can see the detail including deeper information about that selected execution.
-
Providers Report:
This report presents information regarding the Providers. For the selected period of time, information like the total stored volume, active Entities, total number of Assets and Rows is dynamically provided.
-
Stored Volume Analysis Report:
A decomposition tree is displayed with a view on the stored volume of data, broken down by different hierarchical categories – DSU, Provider, Entity and Asset:
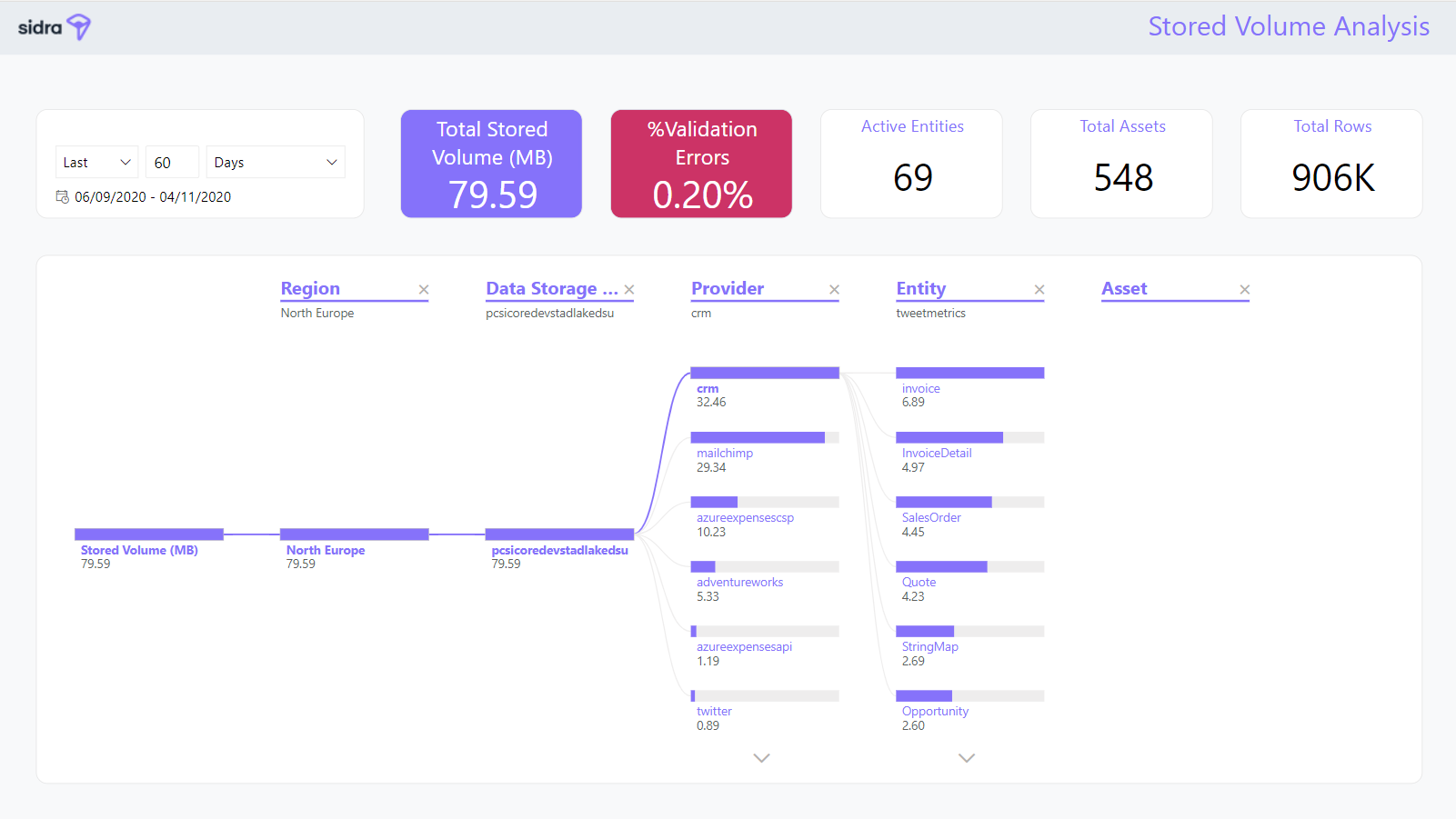
-
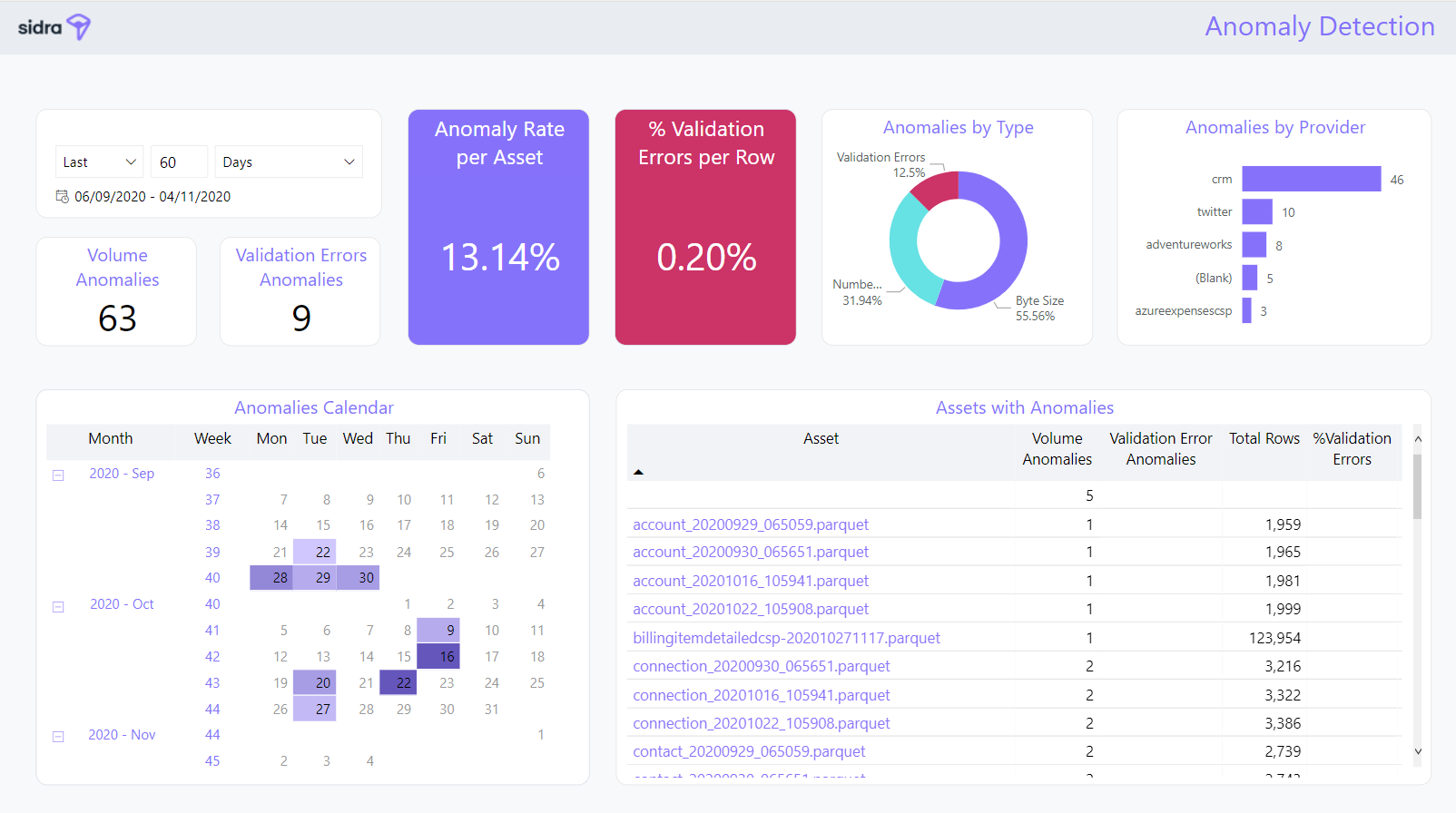
Anomalies Report:
Finally, this report is focused on providing insights into Anomalies Detection at ingestion time. Insights like the rate of anomalies per Asset, distribution of anomalies by type, Provider and Anomaly trends by date are provided by this report.
New Web UI section for Authorization Management¶
As part of our ongoing effort in offering configuration and management capabilities of Sidra through an easy-to-use web interface, we have developed a new section in Sidra Web UI for displaying and managing Balea Authorization Framework.
The system now allows to see all applications registered under Sidra Core and allows to assign and enable roles to users, including mappings, delegated credentials and bespoke permission sets on the underlying resources (DSU, Provider and entity scoped authorization).
According to the different perspectives included in the Balea Authorization framework, the Web UI offers different UI views to manage all entities and relationships of this framework:
-
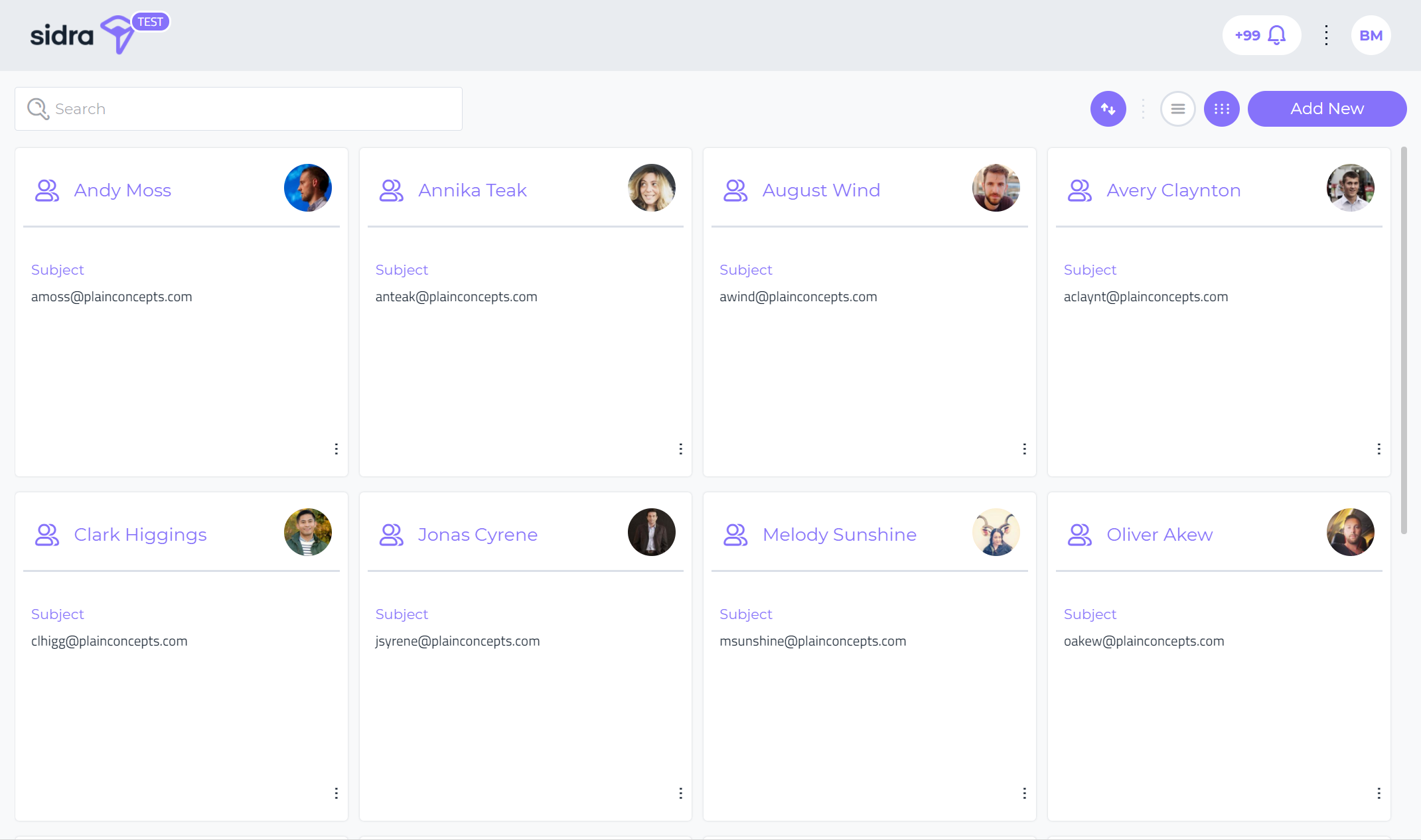
Balea Users View:
From the Balea Users View, Sidra Web users can navigate through all the registered subjects (users) in the Balea Applications. A subject in Balea identifies a user -an individual- or a client -a software system- in the Authorization system.
From each of the User items, it is possible to add new delegations for specific applications, including start and end date of such delegation.
-
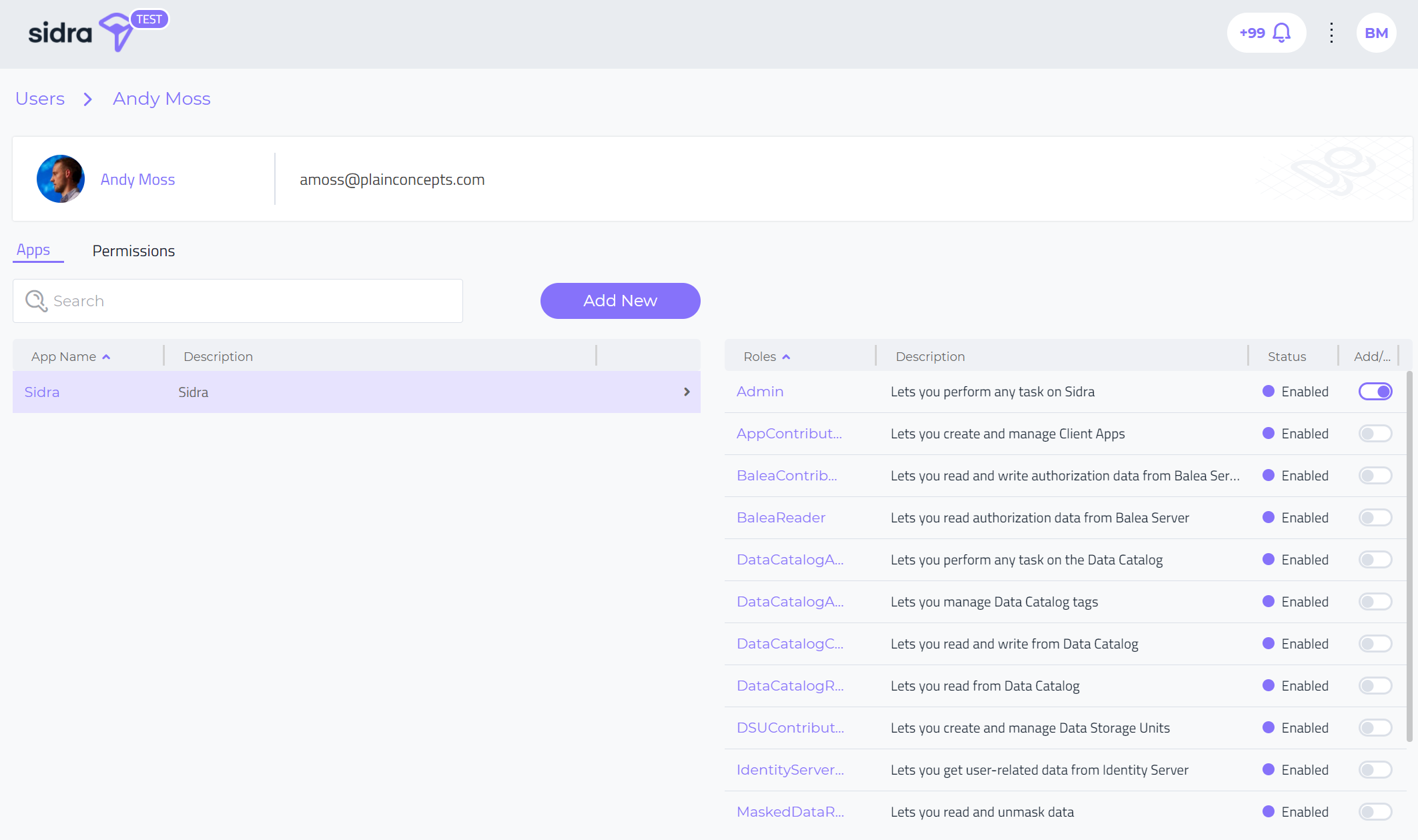
Balea User Detail View:
The Balea User Detail view allows to configure, for each of the Balea subjects, and for each of the application, the following configuration:
- See the list of roles that have been enabled for each application
- Assign/unassign roles to the user for each application
- Edit access level permissions (of the user to the underlying resources (Provider, Entity). A permission is the ability to perform some specific operations in Sidra – read, write, and delete- on the metadata of the resource.
-
Balea Application View:
From the Balea Applications View, Sidra Web users can navigate through all the registered applications with the Balea authorization framework. Balea supports handling the authorization for several applications, so the same subject can have a different set of permissions in each application.
-
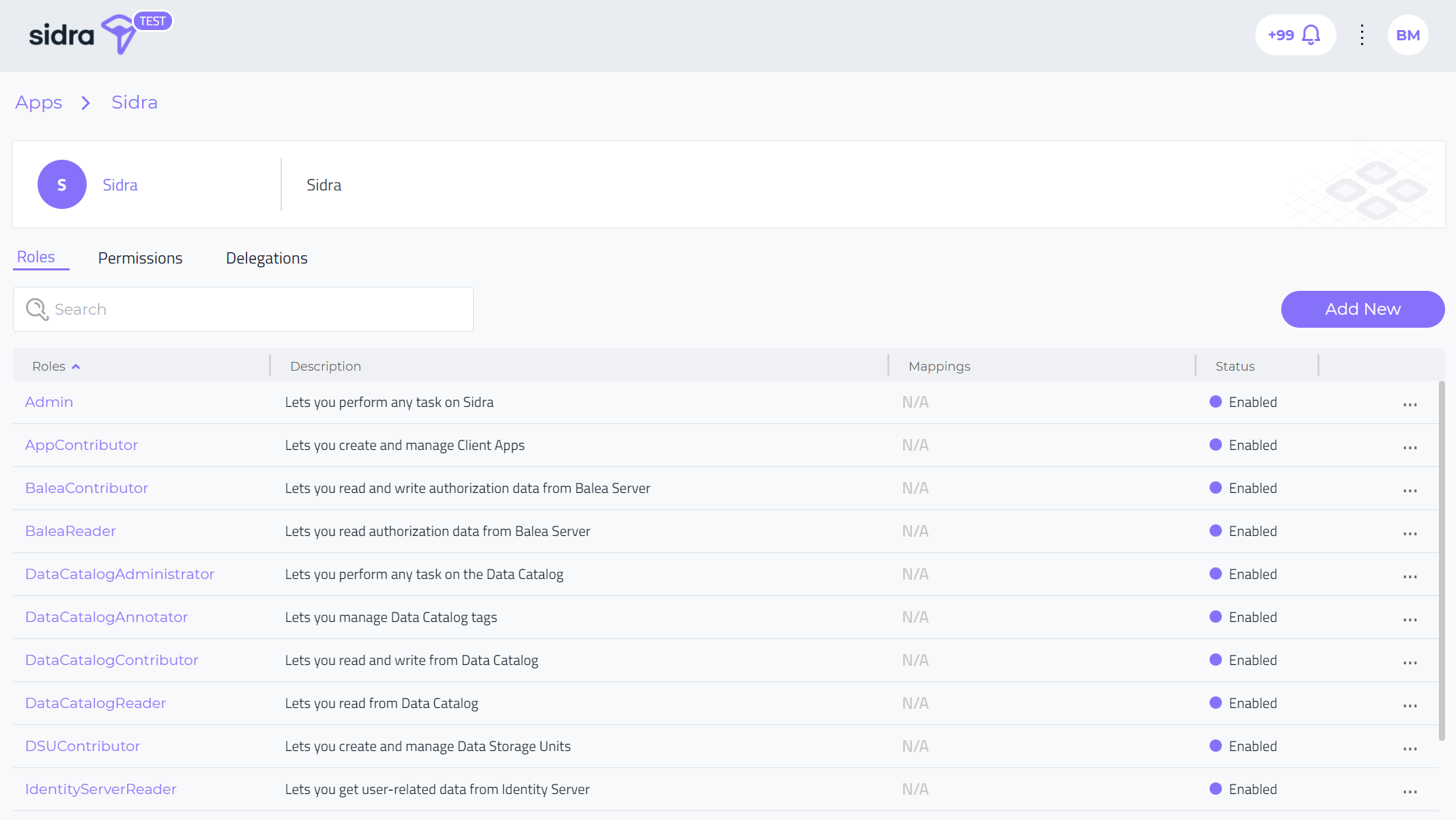
Balea Application Detail View:
A Balea Application can have attached different categories of objects within the Balea Authorization framework.
- Roles
- Permissions
- Delegations
From the Roles menu, the Application detail view allows to perform several actions related to roles management for a specific Balea application: add/edit/delete roles, configure mappings for these roles, as well as enable/disable roles for the specific application. Mappings allow to implement associations between the roles that come from the authentication system and the roles in the Balea Authorization system.
The Permissions menu allows to list and search specific configured permissions that the app has attached (by means of the implicit association between Roles and Permissions in the Balea Authorization model).
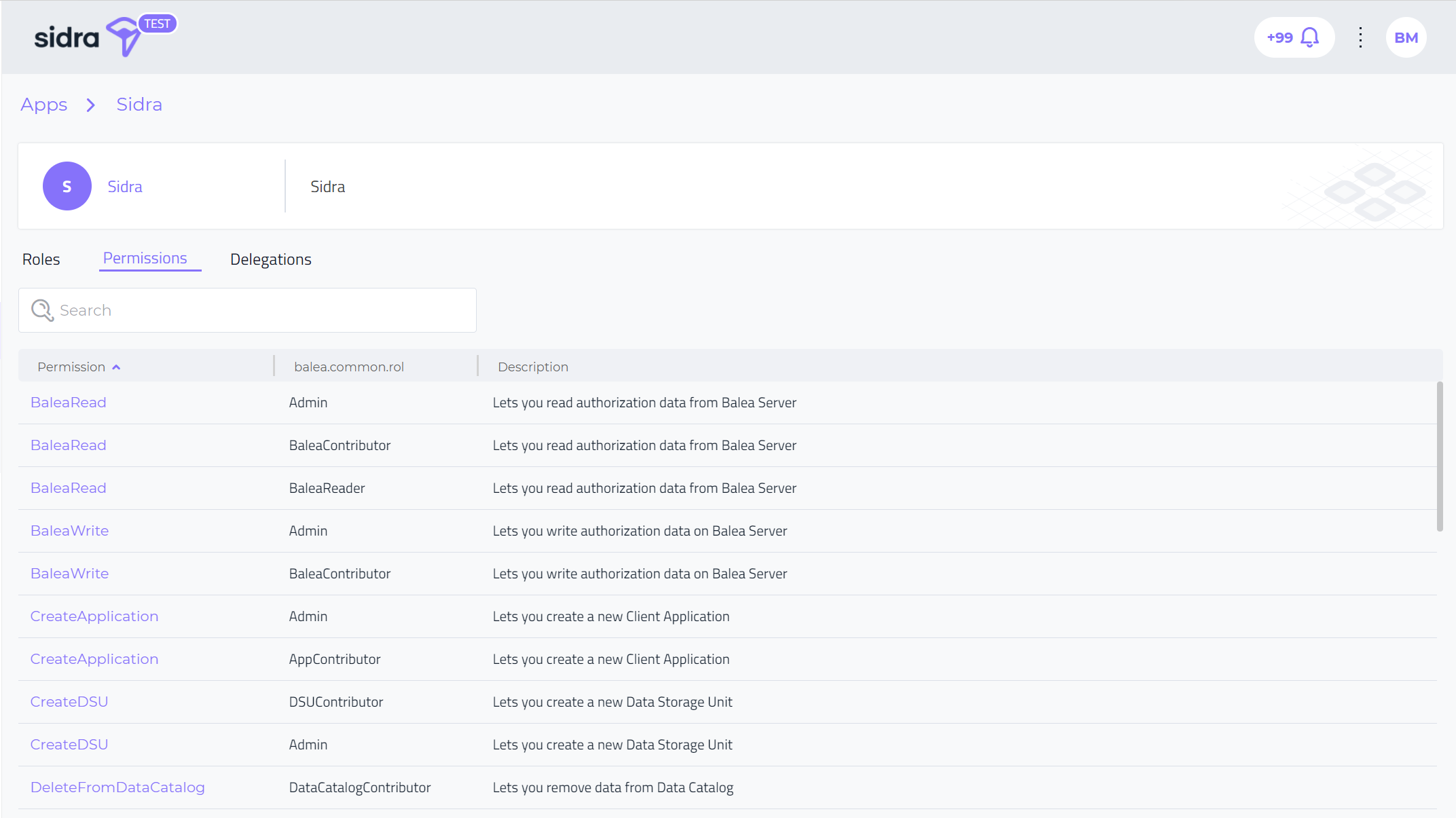
The Delegations menu allows to list and configure permissions delegation between users for a specific Balea application. Delegating a role to second user means this second user can assume a set of permissions to access to the application on behalf of the first user.
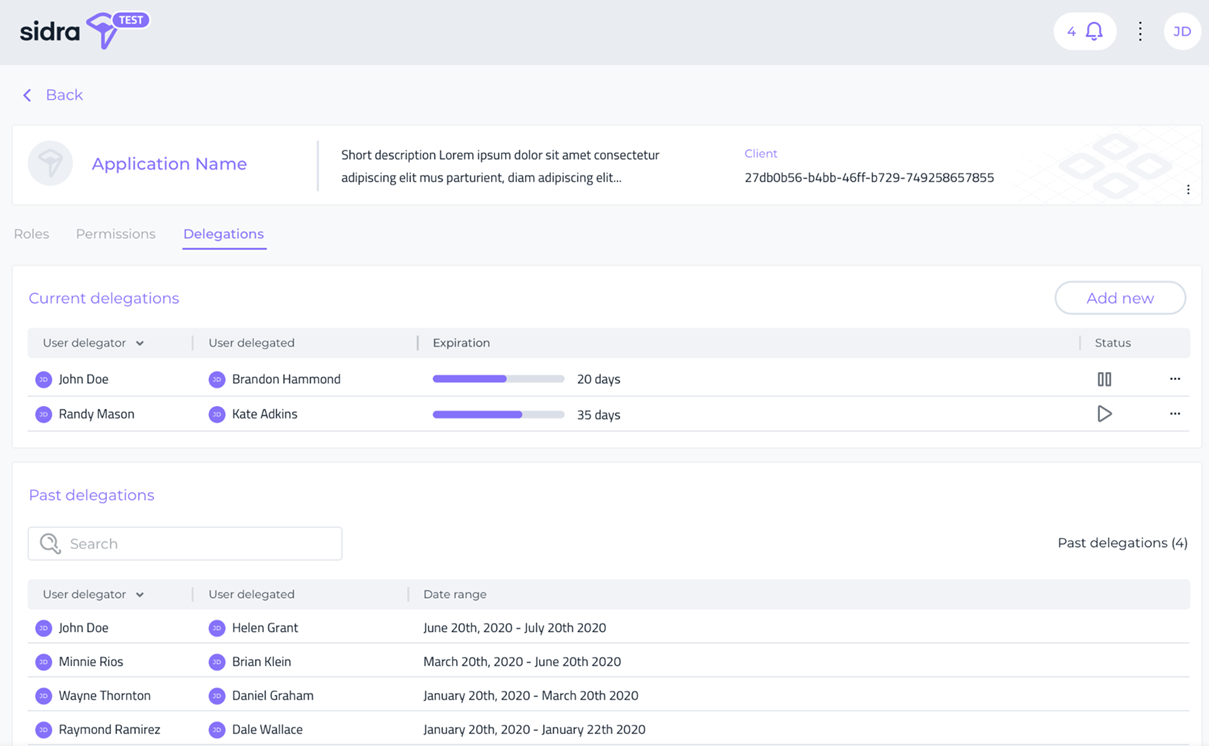
-
Balea API Keys View:
The Balea API Keys view allows to create API keys by configuring their expiration. This View provides the list of API Keys created into the system with their expiration status and allows to delete them as needed.
Improvements to the Azure AI Search pipelines¶
Sidra leverages Azure AI Search pipelines as part of the Knowledge Store capability to process and analyze unstructured types of documents. We have been working on a pipeline template that allows to ingest documents as Assets in Sidra Data Platform, and to create pipelines of Azure and bespoke Plain Concepts knowledge ML tasks, including Optic Character Recognition (OCR) and key phrases extraction over PDF files.
Azure AI Search includes the concept of Skillset, which incorporate consumable AI from Cognitive Services, such as image and text analysis. Therefore, the pipeline can now be easily adapted to accommodate different processing needs by adapting the skillsets configuration or even creating custom skillsets.
During this release, also some operational and usability issues regarding the indexer executions in different scenarios have been improved as part of this feature.
Metadata inference API for CSV files¶
We understood that metadata Asset inference is a key piece of automating and speeding up the process for new entities addition in Sidra. Therefore, we have worked on extending the Assets schema inference by adding the capability to infer CSV file metadata. The Sidra API has been extended to include a new method that receives a Stream of CSV sources and returns the metadata inferred via Microsoft.Data.Analysis package.
New Application Insights Custom Events¶
With this feature we continue building upon the existing observability of the platform and its usage. Application Insights allows to track Web API standard events, like sessions, page views, etc, as well as integrate specific system and API events.
System events captured and centralized include different Identity Server actions, as well as specific data intake API calls.
Additionally, as part of the deployment and operating model defined in the Data Products architecture, we have added with this feature yet another point of standardization with Sidra Core: now Data Products templates will use the Application Insights that is deployed in Core, thus removing the need to deploy any Application Insights instance in the Data Product.
Improvements in Change Tracking for incremental load¶
An option for signalling when to reload all the changes (min valid version) is now useful to control scenarios of expiration of data retention period. Sidra ingestion pipelines now use CHANGE_TRACKING_MIN_VALID_VERSION in SQL to control when Change Tracking can be used to load the changes, and when we need to overwrite the entire table. The improvements incremental load also incorporate support for non change tracking loading logic in SQL pipeline. This has been done by adding a new option to use an incremental query based in parameterization.
In addition, Sidra now supports delete operations in Change Tracking incremental load. The delete support has been incorporated to Transfer Query scripts and we can now support logical deletion through a new metadata field called Sidra_IsRemoved.
Updated Batch Account API version¶
As the API version used in ARM templates to deploy Batch Account is being deprecated, the latest version has been updated in the ARM templates.
Updated Databricks to latest 7.2 runtime version¶
We have updated to latest Databricks 7.2 runtime version, where Apache Spark is upgraded to version 3.0.0.
Unified SignalR hubs for generic handling of notifications¶
In this version, we invested effort on unifying the different types of notifications in the system (Schema detection, Anomaly detection, Webjobs). Notification Types have been added to make this unified mechanism extensible for future notification use cases.
Automatic creation of staging tables for SQL client pipeline¶
While we continue making progress with our major overhaul of Data Products Management model for next version, we have improved the operational overhead of creating staging tables for the SQL Data Product pipelines. From this version we have removed the need to manually create the staging tables needed for such Data Products, so that automatically these tables are created based on the existing metadata.
Issues fixed in Sidra 2020.R3¶
In addition to all the new features of this release, we were able to fix a considerable number of issues, including the following:
- Fixed an issue where the BatchExtractAndIntake pipeline template query could fail due to a wrongly generated query. #97094
- Fixed an issue where the KeyVault helper would fail when the URI ends with a backslash character. #96339
- Improvements to the population of Identity Server's ApiResource and ApiScope when creating a client. #96235
- Fixed an error in which the Transfer Query would insert null records on rows with validation errors when using version 7.x of Databricks Runtime. #96454
- Fixed an error in which the "create_sqlserver_datacatalog_table" procedure would fail due to the JDBC connector not finding a suitable driver. #98142
- Moved the AddUser method from LogContext to the Persistance.Log repository. #97946
- Stopped deploying a local Application Insights in Data Products, so now all Data Products register the activity in Core's Application Insights . #96325
- Fixed an issue in which the AdditionalProperties is not correctly generated during inference process when invalid characters are found. #98209
- Fixed some errors on recent database migrations. #98527
- Fixed and error when generating a token to upload an asset to the landing zone using the date in the path. #97740
- Fixed a condition where Get-AzApplicationInsights was not found when deploying a Data Product by changing to AzureRm command instead. #98228
- Fixed an issue where the authentication request against identity server would fail with a BadRequest response if the client_secret contains special characters. #98222
- Fixed an issue where an ADF activity will fail if the extract inside the ForEach fails, causing the subsequent activities not to be executed as well. #98696
- Fixed an issue where the Identity Server Core client Id returns an incorrectly formatted URL. #97130
- Fixed an issue where entities with certain special characters would fail to load. #98790
- Changed the behaviour when a new application is created so it uses existing roles in Sidra, instead of creating new roles for the App. #96327
- Fixed an issue in which the DatabaseBuilder returns a NPE when ran in localhost. #98733
- Removed the residual Azure Tables support from the ClauseExtraction pipeline template, eliminating issues with large document intake. #97251
- Fixed an error where the application register would fail when granting permissions. #98263
- Changed the DataFactoryMetricLogs process to avoid concurrent executions. #98702
- Fixed an issue where DataFactoryMetrixLog task would not finish. #99043
- Fixed an issue by which the Sidra CLI Update method would fail due to missing IConsole service. #99232
- Fixed an issue where the application registering was failing because endpoint response was missing required output data. #100526
- Fixed an issue where a change in the data type in a field was affecting the view DataLakeVolume. #100927
- Fixed an issue happening when deploying Sidra from scratch in some circumstances, which was preventing DalatakeDeploy from executing properly. #100120
- Changed the behavior of client deployment script for no longer failing if no client database is created. #99982
- Solved an error related to AzureSearchIndexingService background job when using secure context. #100996
- Fixed conversion errors being thrown on view DW DataLakeVolume by changing the data type in a field of the underling table. #100927
- Solved an issue with one WebAPI endpoint, which was not properly checking DatabaseName naming rules. #97855
- Fixed some breaking changes in read_json method from Pandas 1.1.2 that were introduced by Azure Databricks upgrade. #99979
- Solved an issue where in specific scenarios, the pipeline information was not stored in the log table DataFactoryPipelineRun. #100100
- Fixed the retry behavior of GetStorageKey function when requests are timing out. #100629
- Fixed an issue where the deployment always installed the default size (S) in 1.7.1 version. #100728
- Fixed an error that caused, in some deployment script executions, to take wrong priorities to get the information of the installation size in 1.8 version. #100728
- Fixed an issue which, under certain circumstances and when using optional entities to extract, was causing the Data Product extraction pipeline to fail. #97890
- Fixed transfer queries problems when the entity had an escaped character. #99003
- Now Python SDK Authentication module gets token using dictionary in the POST request to guarantee that data is form-encoded and prevent errors with special characters. #98260
- Fixed an issue in GIT operations performed by specific Sidra CLI client installations by using Azure DevOps Personal Access Tokens. #100834
- Fixed an issue where, in some specific scenarios, the KeyVault policy set was failing due to missing configuration. #101553
- Fixed an error on authentication for CreateTable notebook when Client Secret contains some special characters. #98222
- Fixed an issue where, under certain conditions, the databricks linked service was not created correctly. #102347
- Fixed an issue when a query filter was specified as parameters in the API to retrieve the providers. #102741
- Solved different issues rooted in wrong type setting of idProvider in StorageVolumeProvider. #102284
- Solved potential issues when getting tokens for uploading to LandingZone by limiting to Admin user only. #102310
- Fixed issue when trying to parse KeyVault placeholders when pipeline definition JSON is not split into multiple lines. #103521
- Fixed an issue that, under special circumstances, could generate invalid internal credentials to encrypt the data when using encryption pipelines. #103433
Breaking Changes in Sidra 2020.R3¶
Transfer query activities changed from "RunScript" to "RunNotebook"¶
Description¶
This release includes a change in the execution of transfer query activities. From this release, the logic execution of such activities is performed via Jupyter Notebook instead of Python scripts. This change was required to address some limitations in monitoring and debugging of failed transfer queries.
Required Action¶
After upgrading to this release, all transfer queries need to be recreated so they are uploaded as notebooks to Databricks. The location will be in the Databricks workspace, under Shared folder.
Automatically create staging tables¶
Description¶
This release includes a change for automatically creating staging tables for SQL Data Products pipeline.
Required Action¶
The required actions will be needed only for Data Products with database for extracting the content from the DSU and using the pipeline templates provided by Sidra. These required actions consist of: - In your VS solution, remove all staging tables from the database project. These tables will be dropped and created by Sidra each time for the selected entity. - In your orchestrator procedure, alter staging tables to provide any keys or indexes that were in place before to ensure that the query used to read the data is optimized.
Coming soon...¶
It is with great sadness that we announce here that there will be no more releases of Sidra in 2020.
Having said that, we are making good progress internally working on the foundations of the future Sidra Web UI, coming in the first release of 2021. For this next release, we are planning important graphical configuration features to be released, which represent an important step forward in the operability and management of the platform. The new capabilities of Sidra Web will be mostly centered around two big themes:
- Intake connectors step by step graphical user interface, starting with most used connectors across our client base.
- Data Products easy management and creation interface. This leverages the foundations of the new Data Product model and internal API.
On top of this, we are working on further automating Provider Import/Export in order to allow an easy migration along Sidra environments.
Feedback¶
We would love to hear from you! For issues, contact us at [email protected]. You can make a product suggestion, report an issue, ask questions, find answers, and propose new features.