Sidra Data Platform (version 2020.R1: Early Elstar)¶
released on March 10, 2020
The goal for this first major release of the year was to further stabilize the platform after the migration to .Net Core 3.1, focusing on bug fixing and making sure Sidra exploits the benefits of this new platform to its full extents. Having said that, the team has managed to complete the development and testing of quite a large number of new features, making this a very significant release both from and stability and a functional point of view.
We hope this release paves the way for a year full of new features and capabilities; our roadmap for 2020 cannot be more exciting!
Sidra 2020.R1 Release Overview¶
Being mindful that we ended the year with the release of two highly complex features (the migration to .Net Core and the public release of the web UI) the team focused on bug fixing and stabilization of the platform, expecting a significant spike in corrective tasks. However, we were gladly surprised to have less issues and feedback that we expected, so we were able to divert additional capacity of the team on working on some interesting new features. Here are some of the most exciting ones:
- Improvements to the Web UI
- DataFactoryManager performance optimizations
- New Intake ML models for Anomaly Detection
- Performance benchmark
- Documentation Improvements
What's new in Sidra 2020.R1¶
Improvements to the Web UI¶
As was expected, our first GA release of the web UI has revealed quite a considerable number of bugs and areas for improvement, and the focus of this release has been addressing them in the first instance. The following is a non-comprehensive list of improvements made since the last release:
-
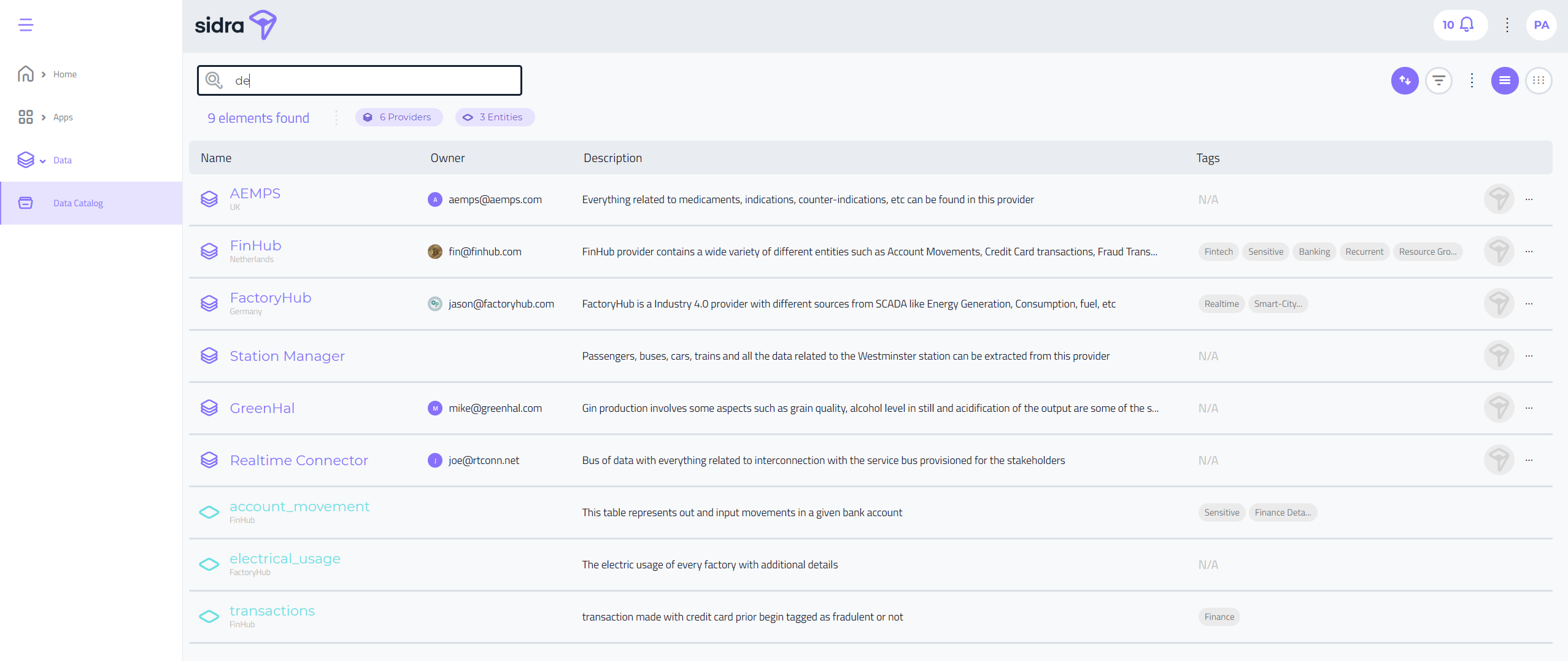
Improved Data Catalog performance:
Some of our customers are using Sidra to ingest very aggressively all the data assets of their companies, with the obvious consequence of having extra large data catalogs on their deployments. The performance on these instances was far from ideal, so a series of optimizations and improvements to the querying strategies have been made over the last months to provide the best experience when browsing and searching through the catalog of providers, entities and attributes. The work is not completed yet, and the team still has some further optimizations on the roadmap, but the improvements so far have improved the experience in a significative way.
-
New action menus on the Data Catalog:
The original user experience for navigating to the details and provider information from the Data Catalog was a placeholder until we could develop the experience our UX team designed for originally. With this release, we are moving to the new icon-based navigation experience which, in addition to be more appealing visually, allows for a better scalability as new actions are added to the interface.
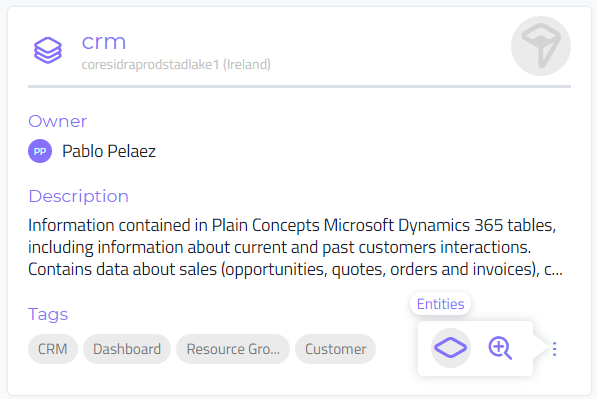
-
New layout for the list view:
We have redesigned the list view for both the App and Data catalogs. The new list is more compact, serving a better purpose when searching and browsing for specific providers or entities, and supports the new action menu introduced on this release.
-
Improved filters:
We have improved the UI for adding multiple filters on an arbitrary number of attributes.
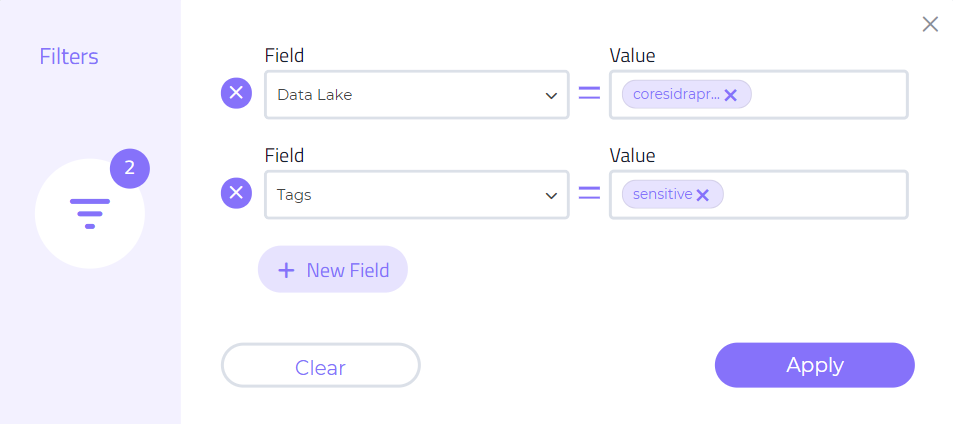
-
Side menu improvements:
The team was not 100% happy with the side menu that was released in the previous version, and it was not working as our design team had expected. For that reason, we decided to rebuild it from scratch and the end result is now, at last, fully faithful to the experience intended originally by our design team.
-
New available services view:
We have added a new experience to browse which Sidra services are installed on the environment. Besides the new visual design, the main purpose of this change was to provide a mechanism where a user can get a detailed information on what each module does, and a notification every time a new module is released and becomes available.
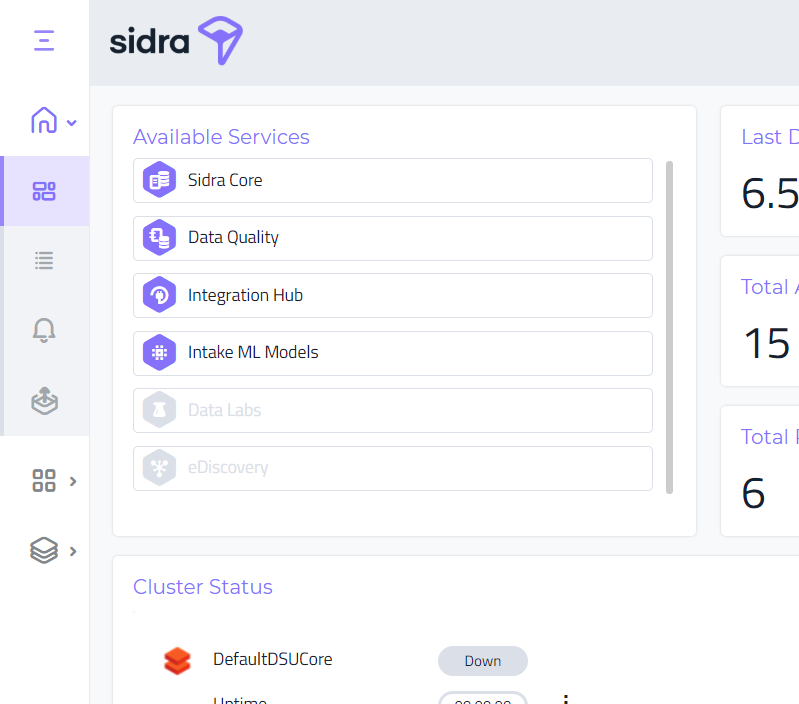
-
Environment Identification:
Based on the suggestion of one of our customer's, we have added an environment identification tag to the management UI. The value is extracted from a new parameter on the frontend web app.
-
Minor cosmetic changes:
A very large number of relatively minor cosmetic changes and improvements were made during these last three months since the last release of 2019. These include greatly improved skeleton screens with loading effects when the data is not yet available, custom illustrations for screens when no data is available, etc.
We are still working on polishing and refining even further the UI, but at this point we are satisfied enough with the results to consider it a solid release for GA.
-
Migration to .Net Core 3.1:
As part of the major effort that was migrating all the code of Sidra to .Net Core 3.1, we have also migrated the web UI. Besides the obvious benefits of running in the latest version - which is also the Long-Term Support version - such as improved performance and availability of additional tooling, running the web in .Net Core 3.1 enables Sidra's web UI to leverage Esquio (see below), as well as the new performance counter model on .Net Core.
-
Esquio Integration:
Thanks to the upgrade to .Net Core 3.1, the UI can now benefit for Esquio, an open source framework for feature toggling, developed by Plain Concepts employees. We are in the process of integrating Esquio to enable features (such as specific gadgets and UI elements) based on security, licenses or even IP mappings for A/b testing.
In addition to all these bug fixes and minor improvements, we have also released a new feature to visualize the system notifications on the Web UI. These notifications are exposed in two different views:
-
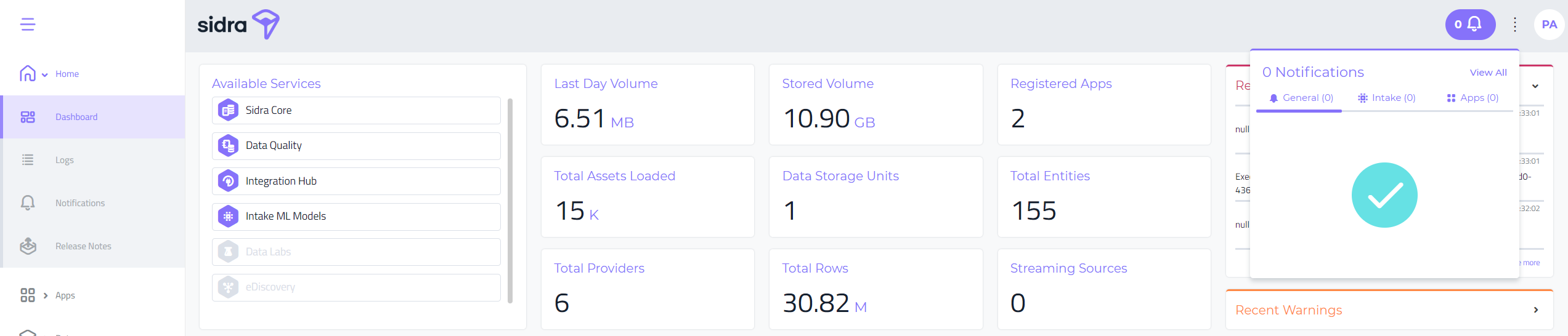
Notifications Widget:
On the top menu, right to the left of the logged user menu, there is a new visual cue of the new unread notifications for this user. The user can click on this and a widget pops up with detailed information on the specific unread notifications, classified by the different categories: General, Intake and Apps.
-
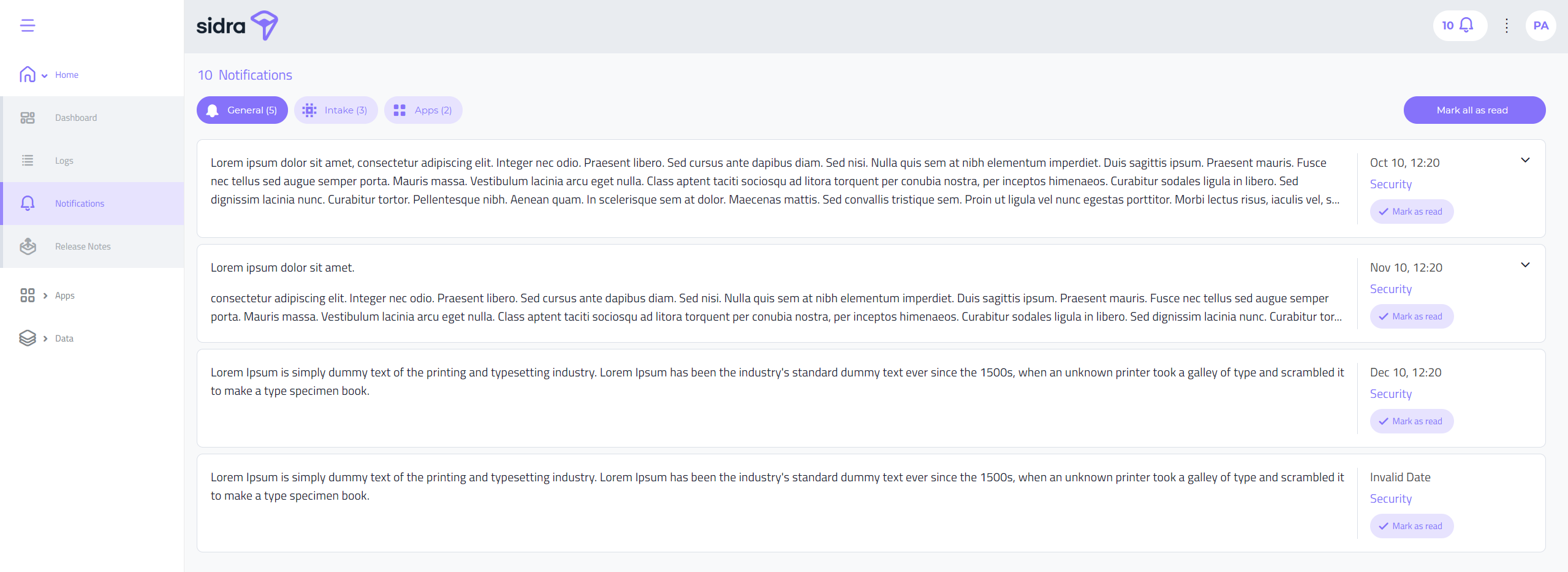
Notifications List:
Besides the notifications widget, a new full-size section has been created to review these notifications with a larger area for the text descriptions. This detailed notification list can be accessed either by the widget, or via the new Notifications menu option, under the Home main menu option.
DataFactoryManager performance optimizations¶
Some of our customers need to bring into their data lakes all the contents of relational databases, which in some cases can amount to many thousands of tables. While Sidra provides the tools to create the intake pipelines in an automated fashion - thanks to the inference API - this process can take a non insignificant amount of time in large scenarios. A series of optimizations on the DataFactoryManager has been performed, which have yielded very considerable performance gains on scenarios with thousands of entities.
As a measure of the performance improvements achieved with the new approach, a test pipeline with 22000 entities took approximately 10 minutes with the legacy mechanism on our test environment, while with the new optimized process it is now completed in less than 4 seconds.
New intake ML models¶
Along with the new SignalR-based notification mechanism released on 2019.R5, and the new notification user interface for the web that we are releasing in this 2020.R1 release, we are updating our Intake ML models to benefit from these new improvements.
The anomaly detection model can be enabled on an Entity-by-Entity basis, and works by constructing several time series for each of the said entities, considering on each of them the impact of the number of rows ingested, the number of bytes ingested and the number of validation errors detected on the specific load. When an anomaly is detected, the system logs the anomaly as a warning on Sidra's log tables and Log Analytics, and also triggers a notification using the new notifications platform.
For the implementation of the anomaly detection model, the following methods have been implemented and evaluated:
- Interquartile Range as a baseline method.
- Behavioural Anomaly Detection (BAD) to consider anomalies at chunk level with inter-dependencies between those chunks.
We will keep on working on improvements to these models during the next iteration, including a refactor of our internal datawarehouse to be able to extract the time taken for each load process of each entity and add it as a feature to the anomaly detection models. Also, for the next iteration we plan to release a new method, based on multi-valued time series.
Performance benchmark¶
The last few releases have seen massive performance increases in different areas of the platform, ranging from metadata registry, pipeline generation and actual data movement performance. It is nice being able to share with our customers that we are unlocking performance gains with each release, but we acknowledge that these performance gains need to be quantified in a more reproducible way. Further to this, and in line with the number of optimizations we have in our immediate roadmap, we also need to be able to detect performance issues or regressions before we release a new Sidra Data Platform version.
During the first quarter of the year, we have worked hard on building a reference dataset, intake pipelines and simulation of customer workloads. We have developed automated performance tests on top of them, so we can track the performance gains or regressions by comparing to a reference baseline. We also commit to make public the performance figures for each of the standard scenarios on every new Sidra release, with an specific section on the release notes.
In addition to that, and in a further exercise of data reproducibility and transparency, we are working on having the dataset and test scenarios to the public over the next couple of months. While we are not yet ready to release due to technical constraints, but this will be available before 2020.R2 is released.
Documentation improvements¶
In the 2019.R5 release notes we acknowledged the fact that, due to the very high pace of development of the platform, our public documentation was becoming both obsolete as a reference guide, and incomplete from a 'hands-on' tutorials point of view. We committed to improve our documentation, and we have devoted a very considerable amount of time to improve it.
Although we acknowledge that there is always room for improvement, we are very happy with the progress so far, and we invite you to check out the technical documentation at https://docs.sidra.dev ,if you have not done so recently. Having said that, our documentation focus will not stop here, and we already have a considerable backlog of activities to improve it even further.
Issues fixed in Sidra 2020.R1¶
This has been a significant release in terms of product stabilization and bug fixing, with some of the more relevant bugs and improvements listed below:
- Fixed an issue in the IngestFromLanding pipeline due to sudden breaking change in the Linked Server JSON schema. #83654
- Hardened the method to extract the fields in the ADF payload, so the previous issue cannot happen again if the JSON schema changes. #84406
- Fixed an error in TransferQuery when the source column name had invalid characters for a Databricks column. #82980
- Improved the HQL file generation mechanism to support larger files, necessary when working with entities with a huge number of attributes. #84382
- Fixed an issue on the AddAsset method, which was failing when folderPath ended with a slash. #82909
- Fixed some issues on Identity Server's database update/migration seeds. #81853
- Fixed an issue with extraction from Google Analytics when the destination container did not exist. #83220
- Fixed and issue with the RetryImport webjob would not properly re-run failed pipelines. #84876
- Performance improvements on the management of Azure Data Factory objects. #84032
- Solved an scenario in which the GetAssetRegisterInfo method would return a NullReferenceException. #84419
- Resolved an issue with long-running scripts in DatabaseBuilder. #84034
- Fixed a typo in the 'log-minimumlevel' parameter of the Visual Studio templates. #84017
- Updated the Integration Runtime download URL for version 4.4.7292. #83949
- The ActivityTemplatesController was missing the Swagger documentation. #85474
Coming soon: Improvements to the Data Catalog and new deployment model¶
From the user experience perspective, our next iteration will focus on improving the surface area of the current Data Catalog. We will enable new Entity and Provider detail pages that will provide additional details, including a data preview for both tabular and media entities. Finally, and time permitting, we will also start the work for providing a simple UI to create new Data Products directly from the web manager.
We are also starting a large piece of work that will change the way the different Sidra components are bootstrapped and deployed; this will be instrumental in implementing our vision for the new data ingestion wizard, but some work is required under the curtains before we can show tangible results. The first and more critical stage is creating an azure deployment service that can build resources programmatically, instead of using our current approach of creating Azure DevOps pipelines on the fly. Once this is ready, the responsibility of the creation of resources such as additional DSUs, Linked Services, Data Product resource groups, etc.. will be on a single location, enabling many scenarios that soon we will share with you.
Feedback¶
We would love to hear from you! For issues, contact us at [email protected]. You can make a product suggestion, report an issue, ask questions, find answers, and propose new features.