Sidra Data Platform (version 2019.R5: Defeated Dougherty)¶
released on September 23, 2019
While most of the team at Plain Concepts and Sidra is getting ready to take some days off for a very well earned rest and some celebrations over this festive period - and the new year that is almost here with us - a big push has been done to release the latest version of Sidra for the year.
We are extremely proud of the work done over these last 12 months, which included massive features such as the new Databricks enabled DSUs, a revamped security model, the migration to .NET Core and a new .NET Core template-based deployment model, as well as relatively minor but extremely useful ones such as the metadata inference system and the PII detection model. Even though there were already a not insignificant number of features released through the year, we were able to finish the implementation and testing of many features that have been worked on for quite some time, making this one of the biggest and more important releases in the history of Sidra. We hope this serves as an appetizer to Santa's presents in a few days!
Wishing all our partners and customers a merry christmas, the team signs off until Sidra 2020.R1!
Sidra 2019.R5 Release Overview¶
Sidra has never meant to be an end-user product, but an enterprise solution to solve data challenges to highly skilled teams. For that reason, the priority of most quality of life features, such as tooling or UI, has always been relatively low: we have always relied on the very capable teams that run Sidra by configuring metadata tables on SQL Server core databases, or inspect the data catalog with Power BI on top of the internal data warehouse. However, during the last year we have been working non-stop in building a solid UI framework for Sidra, supporting a basic view for the Data Catalog, an operational Dashboard and log viewer.
Today we are introducing the web UI release, which is the first step into an incredibly ambitious roadmap that include UI elements not just for data catalog and monitoring, but also new data intake wizards, UI-driven Data Product creation and archival, graphical data archival and retention rules definition, a visual lineage explorer, and many more features.
As part of our constant effort to improve the performance and reduce the cost of the platform, we are also introducing the first of our steps in a larger initiative to remove the dependency on ADF custom activities for the data intake pipelines. This will enable the system to avoid azure batch contention and the delays introduced when the batch instances are not ready and need to start, and it has already shown great improvements on the asset registration tasks.
In Sidra 2019.R4 we finished a quite considerable effort to migrate the system to .NET Core 2.2, which yielded massive benefits from performance and architecture/engineering point of view. In this release, we have gone a bit forward on that migration, moving all the code base to recently released .NET Core 3.1. This allows Sidra to be running on the Long-Term Support branch (LTS) which will ensure support of this version during the next three years.
Finally, as part of this release we have completed several other important features, such as the new Data Encryption mechanism, a new SignalR-based reactive notification system, a new system Data Product (the Integration Hub) for enabling real-time integration with third party systems in a secure and governed way and many bug fixes and general improvements.
Here are some of the key highlights included as Sidra 2019.R5:
- New web UI - Simplifying the operations and data stewardship roles
- Asset Registration without custom activities - Improved data intake performance, and reduced operational costs
- Migration to .NET Core 3.1 - Improved the supportability by running on .Net LTS channel
- New Encryption Model - Increased options for security and compliance
- Integration Hub - New mechanism for communication with Data Products and third-party systems
- Improvements to the Knowledge Store - Improved the support for document processing
What's new in Sidra 2019.R5¶
New web UI¶
After many months of development and testing, we are excited to release to all Sidra customers a new web UI with a very clear goal: help the operations and data stewardship teams to easily manage their platform and data assets. We have an aggressive roadmap in this area for achieving these goals in 2020, but we wanted to release a conservative first version before the year's end to ensure proper testing and feedback from our users, and making sure the foundation we have built enables us to iterate and fine-tune, before diving deep in the next batch of features.
The current feature set includes the following:
-
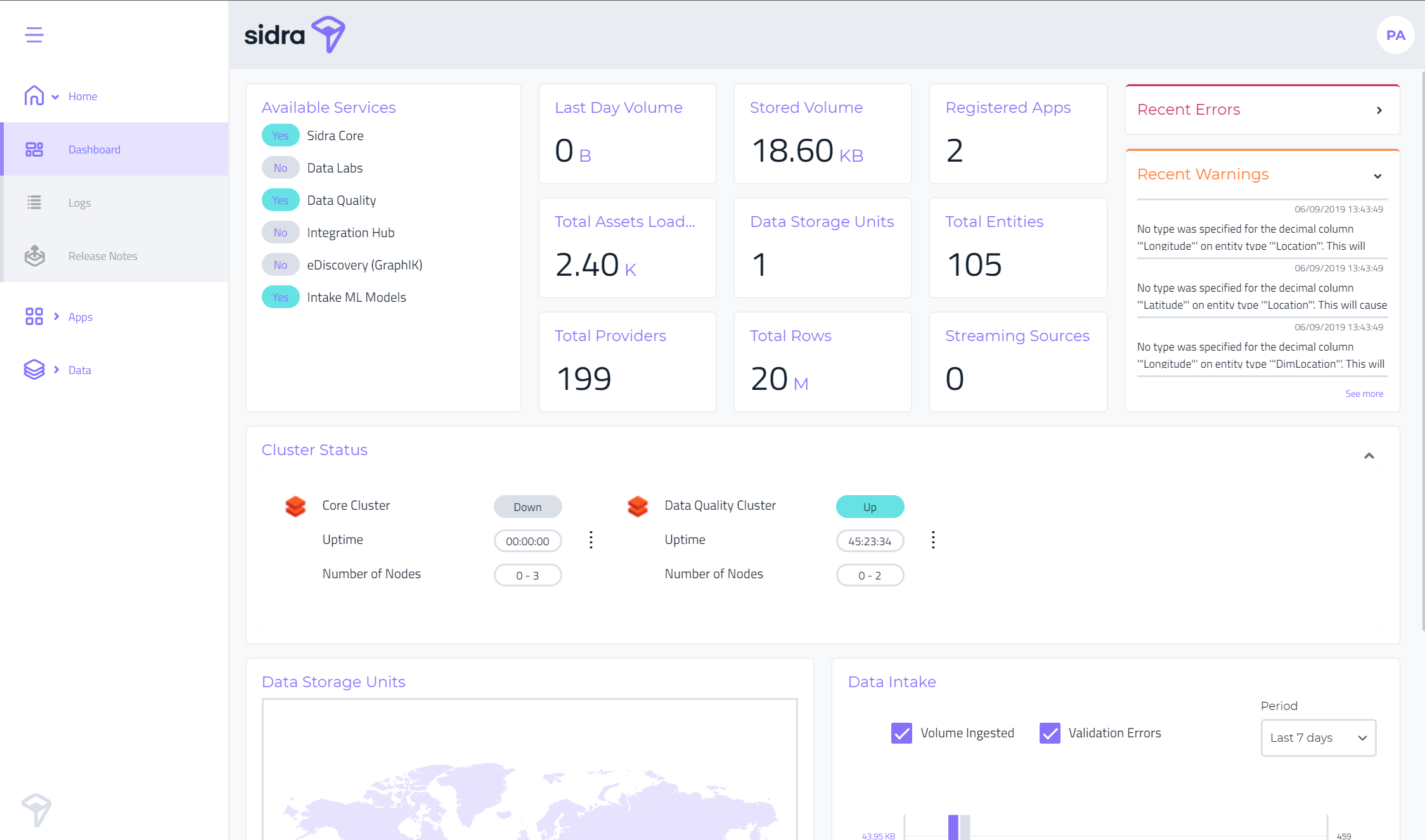
Operational Dashboard:
By providing an overview of the current state of the platform, the operational dashboard acts as a simplified version of the Power BI management dashboards. Basic KPIs are shown, as well as the status of the databricks clusters, an overview of the last errors and warnings and the status of the intake processes over the last days.
-
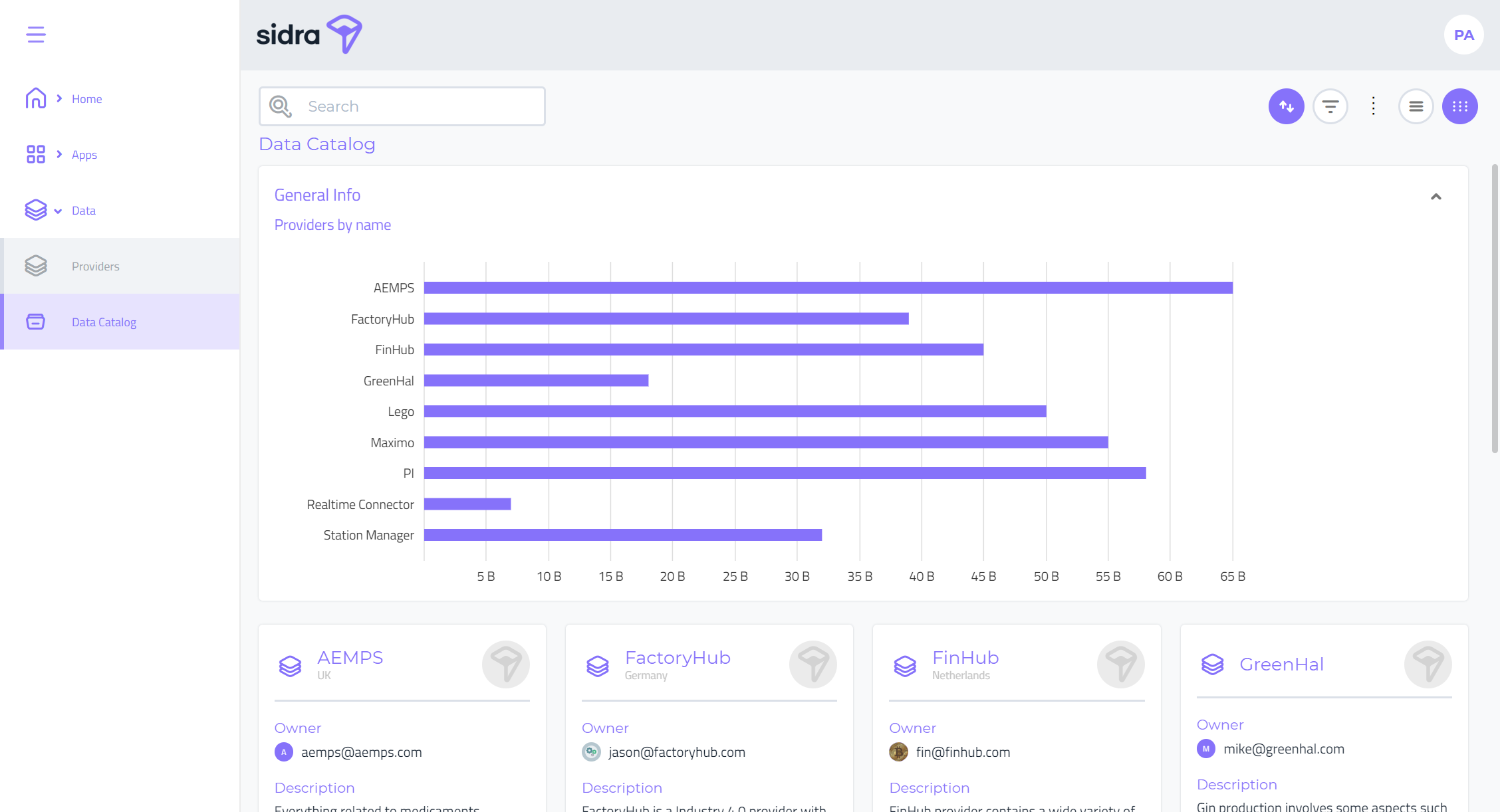
Data Catalog:
From the data catalog view, users can navigate or search through all the Providers and Entities which are visible given the permissions in place. This is a very convenient way of understanding what data assets are available in the platform, allowing search of items by several attributes (such as name, description, owner...) as well as a tag system.
-
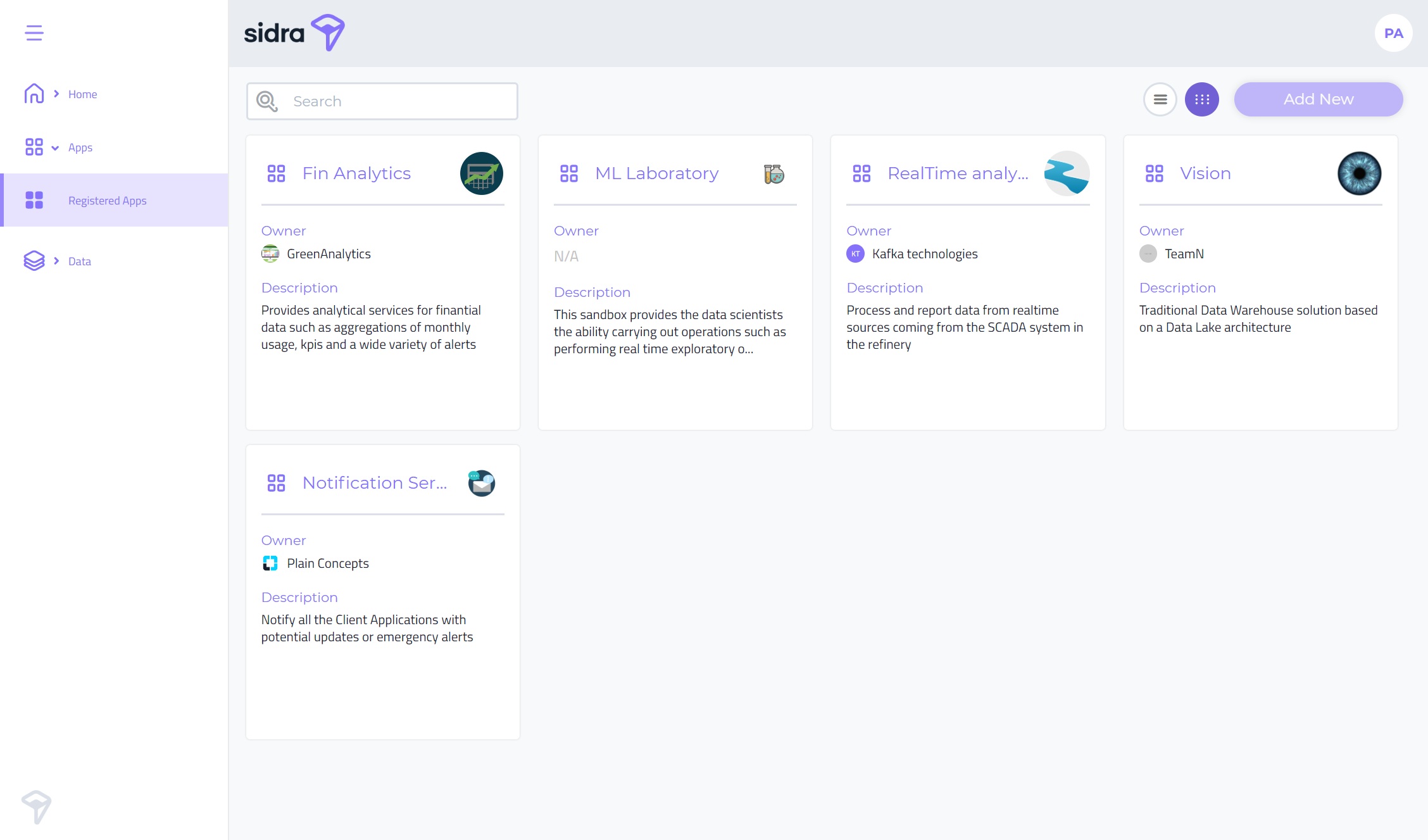
App Catalog:
The Apps catalog allows the user to explore the different Data Products registered on the system. At the time of this release, it is a read-only feature, but the roadmap for 2020 includes the creation of new Data Products from this UI in future releases.
The web is automatically deployed in the Core resource group and integrated with Sidra's Identity Server. It is brandable, so each customer can set it up for alignment with their corporate image in terms of accent colors, logo, etc.
We would like to thank here our very select number of partners that have been testing this feature for the last few months, helping us improve it and ensuring that we have a solid foundation on top of which we can build many additional capabilities.
Asset Registration without custom activities¶
Up until know, Sidra relied extensively on using Azure Data Factory Custom Activities for many custom tasks through all the intake and data movement lifecycle of the data assets. While this approach allows for simple implementation of any specific task just by creating some C# code that will be executed on Azure Batch pools, there are quite a few downsides to it:
-
Batch pool contention:
Tasks get queued in the batch pool and they are executed when there are available slots. During intense operations, such as the load of many small assets, this might lead to queuing.
-
Performance impact of VM start-up:
If a task needs to be executed, and there is currently no VM started and initialized in the pool, the task will need to wait until a new VM has been provisioned and initialized, which can add minutes to the time of execution of the activity.
-
Costs:
Using VMs for executing these task incur in additional operational expenses. Even if this is on a pay-per-use mode, if a way can be devised to execute these tasks on the existing infrastructure of Sidra, these can be reduced in a significant way.
We have started an initiative to reduce the dependency on custom activities, and this release marks the first milestone of our plan, with the re-implementation of the Asset Registration process into our API. This has yielded a massive performance gain, but more importantly, it has provided a good test scenario for this change in architecture, that we are now going to expand to other activities like the Import process.
Migration to .NET Core 3.1¶
Our recent migration to .NET Core 2.2 yielded many benefits, from an increased overall performance to a much simpler and maintainable deployment process based on .NET Core templates, and also gave the team the opportunity to improve some aspects of the code that were tied to the way of working in the days before .NET Core.
This migration has been, without any doubt, the single most important improvement to Sidra over the last 12 months, and has been pivotal for many of the other, more visible features recently released.
We want to commit to the .NET Core version of the platform and, benefiting of the recent release of .NET Core 3.1 - which is the new Long Term Support(LTS) version of the framework - we have migrated all the code in the previous 2.2 version to .NET Core 3.1. This has been much easier than the previous migration, since we were already running in .NET Core, but it was still a considerable endeavour as it impacted the whole set of packages.
We have no plans for further migrations of framework version until the future .NET 5 adoption, so this will ensure us the stability needed to plan for the next big upgrade.
New Encryption Model¶
Even though Microsoft ensures that the data is always encrypted at rest, and that all transmissions are secure on the wire, some customers still need another layer of encryption. We have partnered with some of our customers to build a mode of operation in which the data assets at each DSU can be partially encrypted (some columns are, while others are kept plain), while all raw files are completely encrypted.
This mechanism is not made available to all customers, and can be enabled by configuration.
Integration Hub¶
Quite a few of our customers need to integrate with other real-time systems, such as CRM systems (Dynamics, Salesforce, ...) or line of business applications. To ease these integrations and to ensure that it all falls under the same architecture and security model of Sidra, we have developed a system Data Product that allows the programmatic creation of Service Bus topics, and allows for the synchronization of the data on the topics with delta tables on the DSUs.
This facility is also being used internally by some features we are planning to release next year, including the mechanism to propagate the archival and deletion of entities to Data Products and third-party systems.
Improvements to the Knowledge Store¶
Sidra's Knowledge Store is the mechanism deployed at each DSU that allows the ingestion of unstructured data (from PDF and DOCX files, to video and audio), enrich and augment the data with AI skills and register and secure the assets as any other entity in the system. This is a feature that is being tested at a small number of Sidra users, and under very active development.
As part of this release of Sidra, there has been improvements such as the relocation of the resources to each DSU and the creation of new default pipelines for the knowledge store.
Issues fixed in Sidra 2019.R5¶
This has been a significant release in terms of product stabilization and bug fixing, with some of the more relevant bugs and improvements listed below:
- Fixed an issue where AddAsset would fail if folderPath ended with a slash. #82909
- Improved appsettings placeholder behaviour on the DataFactory Manager. #82572
- Fixed some issues with Identity Server in Llagar backend. #82729
- Improved the behaviour of the Generic repository when using Take or Skip methods. #81852
- Improved the Identity Server database seed behaviour. #81853
- Improved template consistency for Bing and GoogleAds templates. #82133
- Fixed a case of double quotation for columns in generated transfer query. #82808
- Fixed the dependsOn attribute in RunPipeline. #82842
- Fixed the operational dashboard pipeline, which was failing due to a change in Entity definition. #81988
- Fixed an issue where the CreateTableScript did not generate the columns in the correct order. #81441
- Changed the Query controller to support the client credentials auth flow. #81368
- Fixed an issue where the Database Builder was not retrieving the correct folder path. #81057
- Fixed a situation where the Asset registration did not work when path included dates in between assetPath. #80710
- Fixed a rare condition where the Merge statement would not be generated correctly when there were multiple PK fields. 80035
- Fixed an issue with the MergeFactAssets stored procedure for the operational dashboard pipeline. #79717
- Solved many issues on the operational dashboard due to amendments to the Persistence model. #79490
- Massively improved the performance of the Sync operation when synchronizing entities. #80017
Coming soon: Documentation Update, further Custom Activity slaying and Real-time support with Databricks Delta¶
The pace of releases of new features has made it very difficult for the team to keep the public documentation up to date. We acknowledge our failure at this, and the need for improvement in this area, and we have made this a priority for January 2020. We are not planning just an update of the reference documentation so it is consistent with the changes made in Sidra 2019.R5, but also the addition of new tutorials and more reference materials to make the onboard of new customers easier.
We plan to continue with identification of any place where we can substitute the usage of any ADF Custom Activity for an alternative mechanism (API calls, Azure function, etc.) as this is providing better performance and lower operation cost of the platform. We have currently identified several candidates for this change, but this probably will be a recurrent work that will be done iteratively though all the first half of 2020.
Additionally, we are planning to finalize the overhaul of the existing real-time streaming data ingest, based on the new Databricks Delta format.
Feedback¶
We would love to hear from you! For issues, contact us at [email protected]. You can make a product suggestion, report an issue, ask questions, find answers, and propose new features.