Sidra Data Platform (version 2020.R2: Foolish Flamenco)¶
released on May 25, 2020
Sidra 2020.R2 Release Overview¶
Quite often, good things come from of challenging times... and these are indeed challenging times. Our team has worked extremely hard with our current customers and partners to build, without a doubt, the biggest release in the history of Sidra. The Foolish Flamenco release completes the huge security overhaul started with the October 2019 release with the implementation of the new security model on the Extract API, as well as the adoption of Balea, an open-source authorization framework for ASP.NET Core developed by Plain Concepts. We are adding a massive number of key improvements and capabilities to the Data Catalog web UI, including metadata editing for Providers and Entities, Data Preview with data masking support, as well as many other small updates.
From the Data Product perspective we are upgrading our Data Labs app, as well as releasing the first version of a Master Data Management Data Product that will help many enterprise integration scenarios on our existing customers. We are also working on some sizeable changes to the Data Products infrastructure under the hood (stay tuned!), but unfortunately cannot share more details until the next release. However, as part of it, and starting with todays’ release, we are consolidating the Application Insights of the Data Products with the core instance.
Today we are also releasing our first public version of PySidra, the Python package to operate with Sidra's Data Catalog, ML platform, etc. While this has been used internally by Sidra for quite some time now, we are exposing it publicly, as it can be a great addition to the toolbox of any data scientist working with Sidra.
In terms of Sidra DSUs and Core, we are now supporting views and external tables in Databricks, two items that had been on our backlog for way longer than we would have liked. Also, we have made improvements to Sidra's automated deployment model, leveraging the new multi-stage pipelines feature. Last but not least, we have implemented quite a few improvements focused on cost-reduction that will help reduce the operating costs of a default Sidra instance.
This release was originally planned for late June, but after careful consideration it was deemed wiser to release now; as you will see, the number of highly-requested features released today is already quite sizeable, and if we withheld them until June, we would face a release too large to safely plan upgrade paths.
We hope you enjoy this new release. Stay safe!
What's new in Sidra 2020.R2¶
Here is the list of the most relevant improvements made to the platform as part of this release:
- Improvements to the Transfer Query generation
- Major Data Catalog Improvements
- Incremental Load using SQL Server Change Tracking Tables
- New Master Data module
- New Data Labs module
- Operational Expense reduction measures
- Support Views in Databricks
- New Security Model on the Extract
- VPN Injection Support
- Databricks external tables enabled
- API for Linked Services creation
- Greatly simplified default pipelines
- New Authorization model with Balea
- Consolidation of Application Insights for Data Products
- New deployment model with Multi-Stage Pipelines
- PySidra: the new Python package for Sidra
- Minor UI Improvements
Improvements to the Transfer Query generation¶
Back in December we announced the release of a set of DataFactoryManager performance optimizations that were aimed at improving the performance of pipeline creation on scenarios with large number of entities. Today, we are releasing further optimizations for the same scenario, designed to reduce both the cost and time needed for the initial ingestion of large providers..
As it is well known, some of the actions that are automated as part of the creation of a pipeline for a new entity are the generation of the Transfer Query that moves the data from raw to the optimized storage and runs the validations, as well as the table creation on the DSUs. Up until this release, all tables and transfer queries were created one by one when the first asset of a particular entity was ingested. That meant that in large provider scenarios, transfer queries and tables were created one by one when assets started the intake process, resulting in a significant number of executions of custom activities in the Batch Pool, which is costly in terms of both operational costs and time.
From 2020.R2 onwards, the Transfer Queries and the table creation statements are generated in bulk the first time the metadata is extracted from the source using the provider's MetadataExtractor pipeline. This way, queries and table scripts are created in a one-off pipeline, completely avoiding the need for the custom activities.
Major Data Catalog Improvements¶
One of the highlights of this release is the massive number of new features added to our Data Catalog UI. The system now allows to edit the description, owner, and tags of providers and entities, as well as previsualizing the data of each entity in a secured way, with support for data masking based on the user credentials. This allows for a governed documentation and classification of all the data assets in the data lake, and it is mostly aimed at data stewardship roles.
-
Provider Editor:
The new provider editor allows the user to document the providers in depth. Most of the interface real state is dedicated to the documentation editor, which is implemented with an embedded markdown that allows the user to generate rich format documents with links to external documentation, etc.
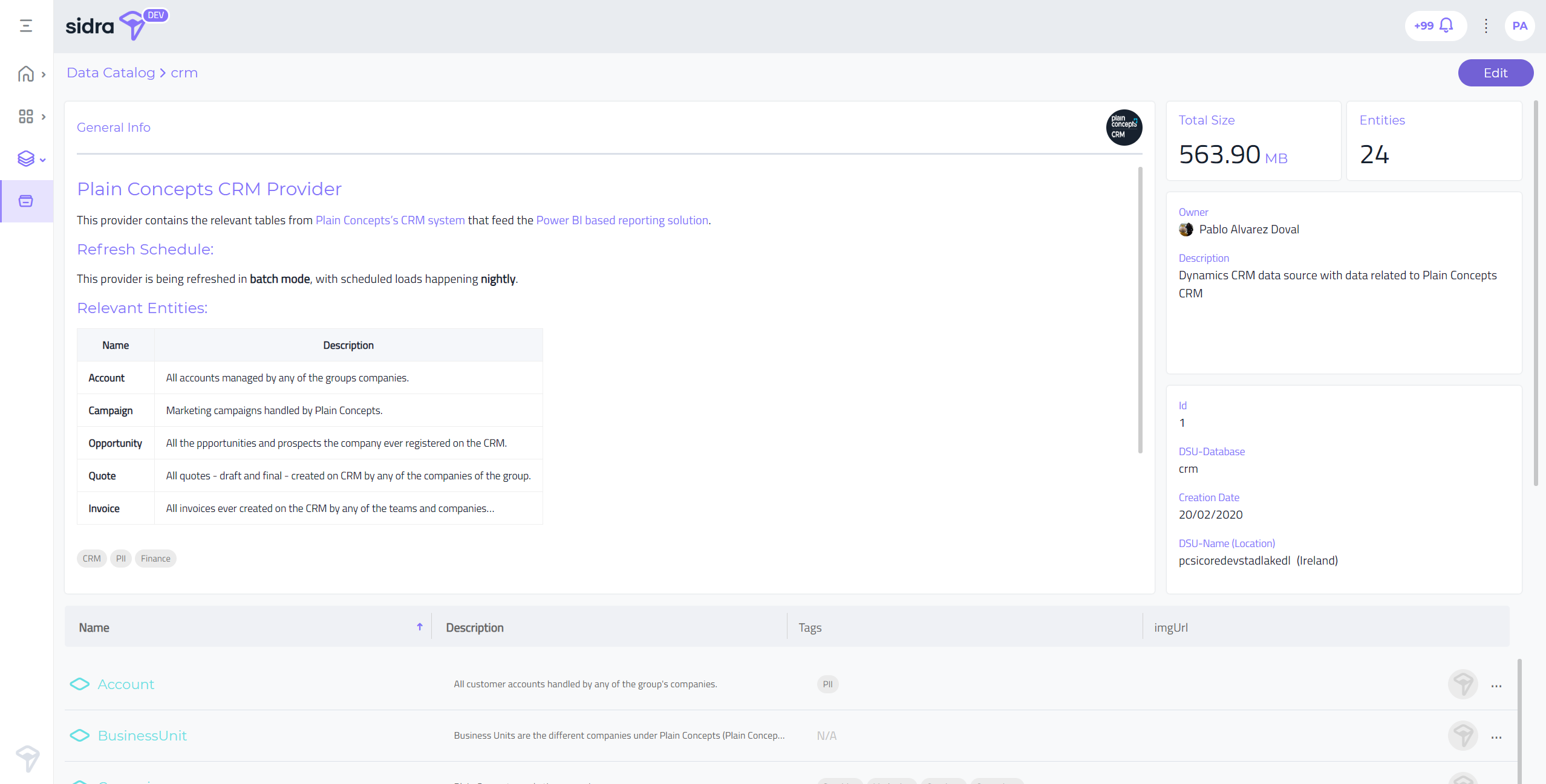
In addition to the documentation editor with real time preview and optional full screen mode, there is also support for editing the provider image, tags, etc:
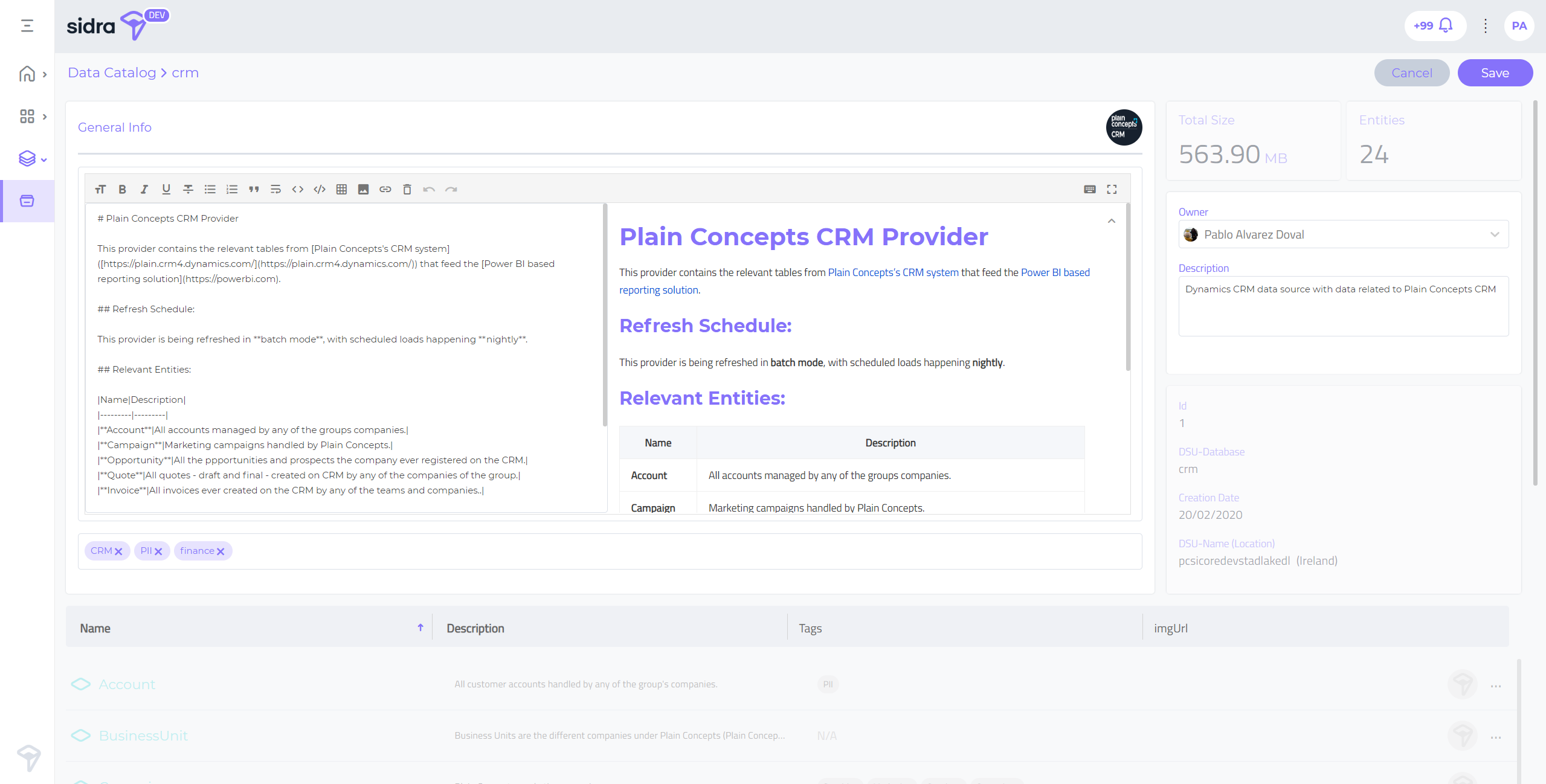
-
Entity Editor:
Entity metadata can now be populated from the UI, including support for entity documentation, tags, and a short description. In addition to that, the entity editor shows the attributes along with the attribute popularity, which is a measure of how often the specific attribute is retrieved by the Data Products in relation to the rest of the entity's attributes.
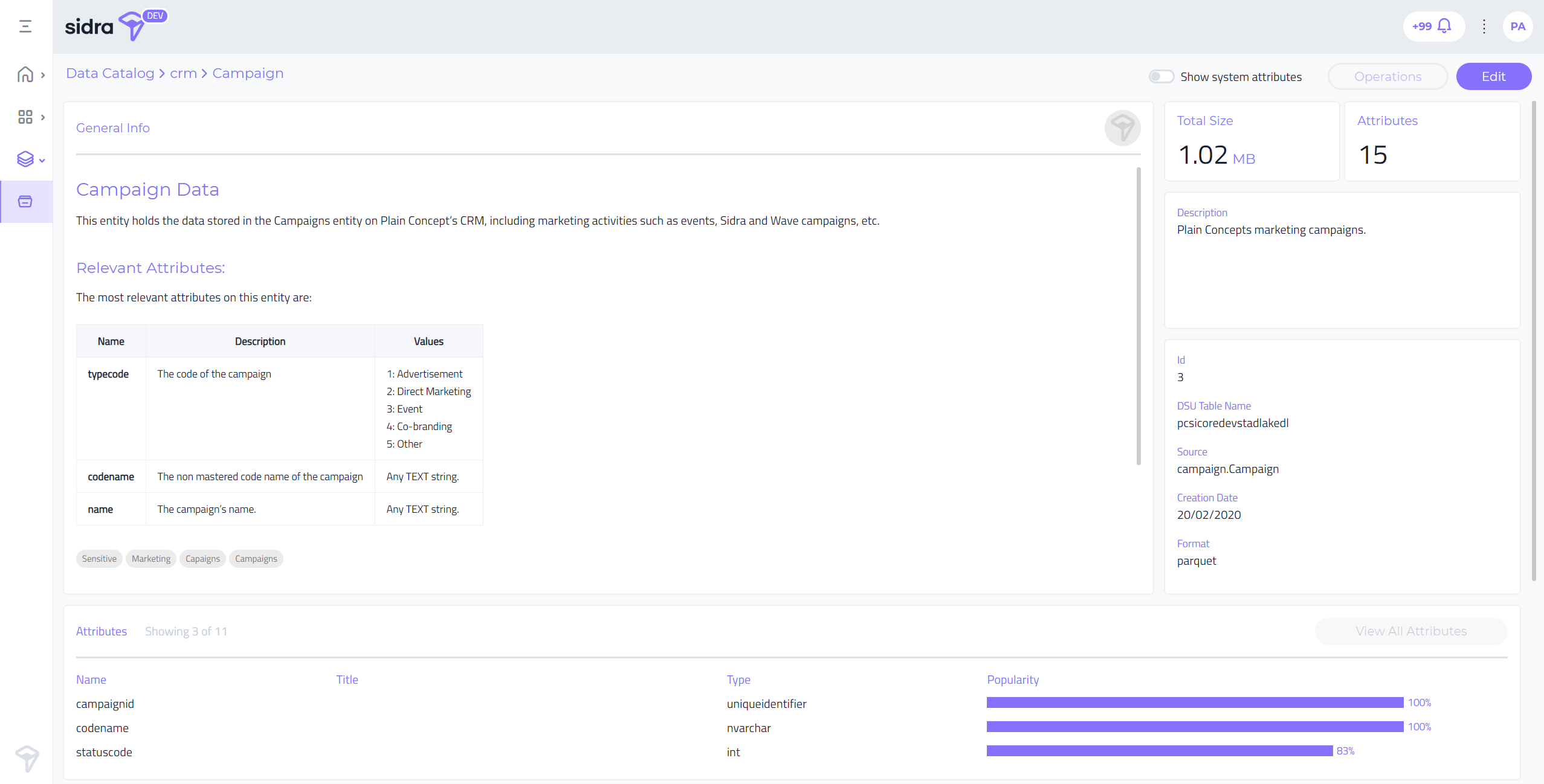
-
Data Preview:
Another long-awaited feature we are releasing as part of Sidra 2020.R2 is the web interface for the data preview of entities:
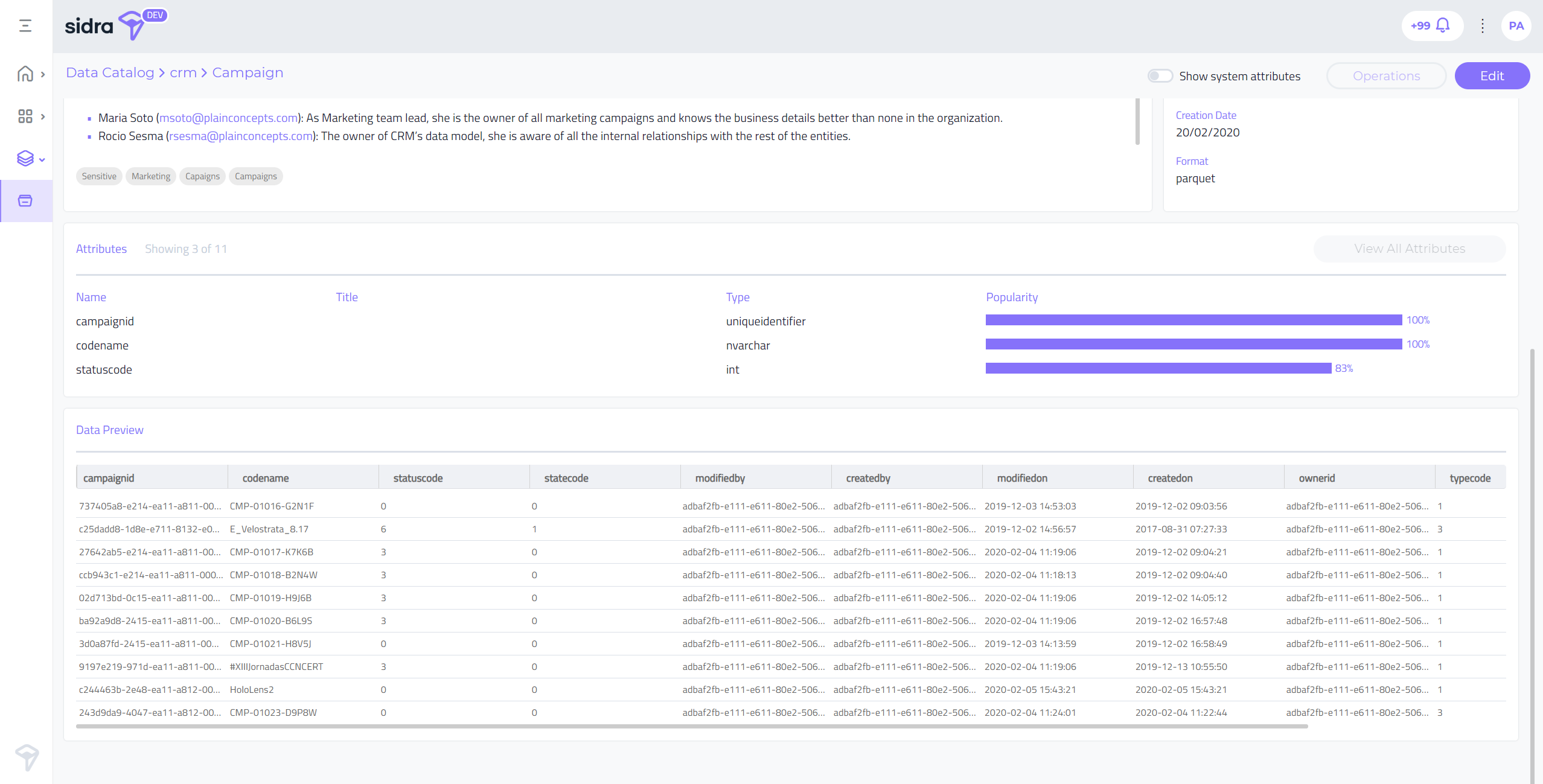
Since some entities might have sensitive data that cannot be exposed to all of the Data Catalog users, specific attributes can be masked, so that all the users that don't have (without) the required permissions will only see the masked version.
By default, and similarly to the attribute pane described above, the system only shows data for the business attributes, hiding all internal Sidra ones. If the user wants to check a data preview for system columns, the "Show system attributes" option can be used to enable them.
In terms of performance, we have also made a series of improvements, both to the frontend and the backend, that dramatically improve the browse and search experience for very large catalog scenarios.
Incremental Load using SQL Server Change Tracking Tables¶
Although we had already helped some customers perform incremental loads by leveraging SQL Server's Change Tracking tables, this feature was not distributed as part of the generally available Sidra release. In this release, we are making the feature GA for all the new deployments, hoping this helps our users speed up incremental loads in an easier and more performant way.
Similarly to the rest of the data load mechanisms on Sidra, the default transactional isolation mode used is Read Uncommitted, so the locks on the source SQL Server database are minimized. However, this is a setting that can be changed via a specific configuration parameter in the event a specific load should not allow for dirty reads.
New Master Data Module¶
The new Master Data module is a Sidra service that enables our customers to centralize business data from several sources into one source of truth. It is convenient to map both identifiers and key attributes across the different providers and systems that are ingested into Sidra, as well as for internal tracking of entities for scenarios such as data archival and retention across multiple Data Products or third-party systems.
The module exposes an API that allows customers to access the data from mastered entities, without the need to know exactly which sources are needed to be queried; just by querying for the business entity to the Master Data API, all the relevant information will be returned. In addition to that, there is a mapping feature that allows correlating the same business entity by knowing each primary key between all the sources.
New Data Labs Module¶
We have rebuilt the Data Labs module to provide not just a local Databricks environment, but also the ability to synch the tables on SQL Database tables for more traditional analytics scenarios. The module has also been upgraded to .Net Core 3.1 to align with the rest of the platform.
Operational Expense reduction measures¶
As part of this release, we have made several changes to greatly reduce to operational costs of the platform, including the following:
- The AKS services are now an optional deployment on each DSU, so the Sidra installations that don't use any feature that requires it (such as the knowledge store) will see their Azure consumption greatly reduced.
- The operational dashboard is no longer updated using ADF pipelines, but with an internal built-in synchronization mechanism. This results in a considerable cost reduction, as well as the improvement of the dashboard update latency from 15 minutes down to just 60 seconds.
- The new default for the Data Integration Units (DIU) in Data Factory has been changed from 4 down to 2, which is a perfectly valid configuration for the vast majority of the cases and results in fewer activities being executed.
- Further reduction of the total number of Custom Activities, reducing the dependency and usage of the Batch Pool service, which is one of the most expensive Azure services used by Sidra.
Support Views in Databricks¶
Sidra now allows for the creation of composite views of multiple entities and exposing them to the Data Products as a new, native entity. These entities depend on a Databricks query, instead of being loaded directly from a set of assets.
An example of their usage is providing a composite view of email campaigns from a Mailchimp platform and customer contact information from a CRM system; in this scenario, we might want to have a single entity exposed to Data Products that is the result of an Inner Join executed on top of these two data sets. Once both assets have been loaded into the DSU, Sidra will automatically trigger the execution of a view and expose that as an Entity on the Data Catalog.
New Security Model on the Extract¶
We have finalized our long security overhaul with the last component that needed to be updated: the extract that synchronizes data from the DSUs to the Data Products. We are now improving the way the Data Products' Identity Server is used, and how the security restrictions are enforced.
This new security model also implies the removal of the Extract custom activity, further contributing to the overarching objective of removing/reducing all dependencies on Custom Activities and the Azure Batch service. This reduces the operational costs and, more importantly, increases the performance, since the overhead of executing the security injection in the batch account is no longer needed.
VPN Injection Support¶
Some of our customers are currently running their Sidra instances inside a VPN on Azure, but this was always achieved as bespoke customizations of their deployment processes. As of today, we are providing out-of-the-box support for VPN Injection of any new Sidra deployment. This will not just help new customers with VPN integration requirements to be onboarded quickly, but more importantly, it will enable all current and future customers with VPN injection needs to experience much quicker and effortless migration to new versions, as they will no longer need special release processes.
VPN Injection Support¶
Some of our customers are currently running their Sidra instances inside a VPN on Azure, but this was always achieved as bespoke customizations of their deployment processes. As of today, we are providing out-of-the-box support for VPN Injection of any new Sidra deployment. This will not just help new customers with VPN integration requirements to be onboarded quickly, but more importantly, it will enable all current and future customers with VPN injection needs to experience much quicker and effortless migration to new versions, as they will no longer need special release processes.
Databricks external tables enabled¶
A bit of background around Sidra's development: back in the early days, there was no support at all for Databricks - mainly because it was not a thing, yet! :) - with all DSUs powered by HDInsight. Once Databricks was born we created Databricks-powered DSUs, which are the new standard being used in all of our customers. Due to technical considerations, when this was implemented we had to give away the external tables support and rely on the internal Databricks storage, which was a deviation from our original approach back in the HDInsight days.
We are very happy to announce today that, after a considerable development effort, we are again able to provide support for external tables, by relying on an external ADLS Gen2 storage (actually, Azure Blob Storage with hierarchical namespaces enabled) for each DSU available. This layout will be optional, but it will be the new default configuration for any newly created DSU.
API for Linked Services Creation¶
One of the most tedious activities required to set up a data intake pipeline from a new data source is setting up the ADF's Linked Services, as it requires a considerable amount of modifications, and a new deployment of the Core. In this release, we are releasing a new controller on Sidra's API to cater to the creation of new Linked Services, allowing this process to be more automated, and greatly improving the experience of adding new providers.
This capability will become a major enabler for additional exciting, high-impact features we have on the roadmap, which will be announced later this year.
Greatly Simplified default pipelines¶
A review of the current default pipelines was performed in order to implement all the changes to the security approach. We took this opportunity to review and simplify some of the current templates, to reduce complexity and the total activity count, which will render performance improvements and cost savings.
New Authorization model with Balea¶
One of the highlights of this release is the integration with the Balea Authorization Framework, which is an open-source initiative led by Plain Concepts that provides a comprehensive authorization framework for ASP.NET Core. This enables to have a generalist, non Sidra-specific authorization middleware that can be used both for the core and Data Products.
Sidra leverages Balea to enable:
- DSU, Provider and Entity scoped authorization
- Role Management
- Impersonation and Delegated Credentials with constraints
- Mappings
- Bespoke permission sets
Consolidation of Application Insights for Data Products¶
We are working hard on a major upgrade of the Data Products model; while it is too early to share the roadmap for the new model, we are releasing minor changes that will be part of the larger picture. One of them is the consolidation of the application insight instances for the Data Products. Starting with this release, all Data Products will use the centric, core-based instance of Application Insights. This helps with the consolidation of logs and metrics, and under certain scenarios, can help reduce the operational expenses of the platform.
New deployment model with Multi-Stage Pipelines¶
Starting with this release Sidra has adopted, both in the core and Data Products, the new deployment pipelines model proposed by Microsoft as part of its Azure DevOps platform: the Multi-stage pipelines.
This has provided the following benefits: - More complex pipelines can be defined, with automatic retry of failed stages - Now both CI and CD pipelines are defined with YAML, with improves the consistency of the pipeline definitions - By using YAML instead of JSON for the definition files, parameterization can be introduced, simplifying programmatic edition
Overall, thanks to this change, new releases of Sidra will be easier to deploy and less prone to deployment issues.
PySidra: the new Python package for Sidra¶
PySidra is a Python package whose main goal is to provide objects and methods to properly communicate with Sidra's API. While the package was available internally to the Sidra dev team for quite some time, today we are making it generally available to all users. This is of special interest to data scientists who want to access the data securely, and perform exploratory data analysis, modelling, etc.
Minor UI Improvements¶
In addition to the large number of improvements to the Data Catalog, and the performance improvements around the whole Web experience, we have also taken the time to polished the existing UI with some welcomed additions, including:
- Resizable tables for logs, data preview, and provider/entity list mode
- Improved grid behaviour, with sorting widgets, etc...
- Improved readability of the Anomaly Detection system notifications
- New and much improved toast notifications
- Improved markdown renderer for the Release Notes section on the web UI
Issues fixed in Sidra 2020.R2¶
In addition to all the new features of this release, we were able to fix a considerable number of issues, including the following:
- Fixed an issue where, under certain conditions, the data types where not correctly inferred on DB2 sources. #90310
- Fixed an issue where the triggers in Data Factory are not correctly deleted before a dependant pipeline. #90360
- Fixed an issue where, for certain data types and with specific data type casing, the DB2 source schema inference would resolve incorrect data types. #90310
- Fixed an issue where the inference of SQL Server schema would fail when working with the old, unsupported IMAGE or TEXT types. #87005
- Instead of relying only on convection for the Data Product names, we are now supporting an optional parameter for the Data Product to register in the Core database. #86565
- Fixed an issue where the incremental pipelines would not use the source name field of the attribute. #85716
- When defining a new scope, the ApiResource topics are missing when using the CreateClientInIdentityServer stored procedure. #85661
- Modified the convention for ClientName to use a combination of ProjectName and ProductName. #86612
- Solved an issue with the DataFactoryLogs pipeline in Data Factory. #85351
- Fixed a memory leak on the Sync webjob. #87869
- Removed quite a few recurrent errors and warnings on the system logs. #88194
- Removed the deprecated parameter 'ColumnDelimiter' from the IncrementalLoadAzureSQL pipeline. #86625
- Fixed an issue where the default size for the core database was not valid. #86104
- Fixed an issue where, under certain conditions, the Providers endpoint would not return the owner's info. #87112
- Fixed an issue preventing ADF to send the metrics to Sidra's Log Analytics. #87252
- Fixed an issue where, under certain conditions, the LandingZones/token endpoint would return a 500 error code. #87121
Breaking Changes in Sidra 2020.R2¶
IngestFromLanding pipeline renamed to RegisterAsset¶
Description¶
One of Sidra's main pipelines is "IngestFromLanding". The name of this pipeline caused some confusion since the pipeline is not only used to ingest data left in the landing zone but also to register any file left at any location in the Azure Storage staging account, providing the correct fileName and folderPath parameters.
For that reason, the pipeline has been renamed to RegisterAsset, providing a better context on what the pipeline actually does.
Required Action¶
- The IngestFromLanding pipeline must be manually removed from the DSU Data Factories' instances.
- Any pipeline that contains a RunPipeline activity with a reference to IngestFromLanding must be updated to reference the new RegisterAsset.
Changes in Sidra Python SDK¶
Description¶
There is a new module called api which now contains all the wrapper code of Sidra API. The existing code was moved to it. This change was necessary to separate this responsibility from the other kind of functionality that is going to be developed in this package. Also, some imports in the shape of
client.clienthave been simplified toclient.Required Action¶
Modify the import clause of this package from:
to:
Changes in Python packages¶
Description¶
From now, in order to keep a homogeneous version numbering, simplify the development, and be able to maintain a separate and compatible branch for each previous release of Sidra, the Sidra Python SDK, AnomalyDetection and TextExtractors packages use the same convention for version numbering as the main Sidra projects.
Required Action¶
Add explicitly the version of the Python package when installing it, either locally or on Databricks. Indeed, init-script.sh was properly modified in dev and Release-1.6 to point to the correct version of these packages (1.7.x and 1.6.x, respectively)
Changes to the Database Tier on the Deployment Script¶
Description¶
We are now providing more flexibility in the selection of the database size and tier on the deployment process, but this change can affect the way that you define the tier of your databases.
In previous versions, there was just one parameter in PSD1 files to cover that:
Now we are exposing two parameters, with slightly different semantics:
ClientDatabaseServiceObjective: { S1 | S2 ... | P4 | .. etc} ClientDatabaseSizeInGB : 100, 200, etc.This provides a better solution to specify the size of the database, as well as helps tidying up the database template when not using canned size installations.
NOTE: The Size must be compatible with the ServiceObjective selected.
Required Action¶
Your deployment scripts might need to be changed. For further details, check the documentation inside the package.
Changes to the Integration Hub¶
Description¶
As part of Sidra 2020.R2, we have published the version 1.7.0 of PlainConcepts.Sidra.App.IntegrationHub package, that replaces the old PlainConcepts.Sidra.EventBus, and can be found here: https://www.myget.org/feed/plainconcepts-sidra/package/nuget/PlainConcepts.Sidra.App.IntegrationHub
Existing Sidra deployments will not be automatically upgraded by re-deploy, as the package name has changed. To update to this new version, the host app needs to be re-created using the template (also upgraded). Note that this version has been upgraded to .Net Core 3.1, to be kept in line with the rest of the pieces of Sidra 2020.R2.
Required Action¶
If your environment uses the Integration Hub, the host app will need to be re-created with the new version of the package. Since the "eventbus" was used not only in the package name or namespaces, but also in IdentityServer scopes and resources, when deploying over an existing IS, you can use a script included in the project to rename the default scopes, resources, etc. to the names expected by this version.
Data preview feature requires a change in the release¶
Description¶
Due to some new requirements part in the Data Preview feature, the step "Infrastructure: DataBricks" from Core release now takes an additional parameter (-coreJdbcConnectionString "$(coreJdbcConnectionString)"). The variable "coreJdbcConnectionString" is published from the CoreDeploy.ps1 script, in the previous step from the release (Infrastructure: Core)
Required Action¶
Add the following to the "Infrastructure: DataBricks" step in the Core release pipeline:
AKS deployment has been moved to DSU deployment step and is now optional¶
Description¶
The deployment of both the AKS service and the Azure Machine Learning Workspace has been moved to the DatalakeDeploy.ps1, with the deployment of the AKS being optional now. The Data.psd1 script now accepts the variable AksDeploy, which defaults to false.
Required Action¶
In order to update the release pipelines, it is needed to add the parameter "managerApplicationSecret" with Pipeline.ClientSecret value to the DatalakeDeploy.ps1 step in the Core release. Also, to make AKS optional add AksDeploy='false' to your environment psd1 file.
Balea feature needs a change in the WebApi project template¶
Description¶
The addition of the Balea authorization framework requires changes to the WebApi project.
Required Action¶
The Balea integration includes a change in the template of the WebApi project, so it needs to be updated.
Two scopes addition for integration between API and IS¶
Description¶
For proper integration between the API and IS, we now require two scopes (plainconcepts.sidra.api and IdentityServerApi)
Some pipelines where failing because they were using a token with one the first one. I´ve changed the templates and the pipelines´ LastUpdated field so they will be updated during deployment.
There are two templates (below) which are not being used in any pipeline in Core´s seed. I guess we have pipelines using them on some client that are not in the seed. When updating to 1.7 you will need to update those so they peek the fixed template.
INSERT_METADATA_USING_DB2_SCHEMA_PIPELINE_ID INSERT_METADATA_USING_TSQL_SCHEMA_PIPELINE_IDRequired Action¶
Update the following pipelines if using it in the customer implementation:
Coming soon...¶
As a result of the massive amount of changes and improvements to the platform released as part of Sidra 2020.R2, we are planning a stabilization sprint ahead. We plan to shift our focus to engineering tasks, including the long-awaited refactor of certain entities (no longer DataLake tables and controllers instead of DSUs!), so the number of new features will be smaller than the first two releases of this year.
Having said that, we are planning two large items to be released on 2020.R3:
- New Data Product model, including internal API, new deployment model and hopefully, management via the web UI
- Web UI for the Balea authorization framework
Feedback¶
We would love to hear from you! For issues, contact us at info@sidra.dev. You can make a product suggestion, report an issue, ask questions, find answers, and propose new features.